No nosso último papo aqui no Cuca Fresca sobre Nutanix, falamos sobre o mito da controladora de storage centralizada. Vimos como o AOS e a CVM (Controller VM) democratizaram a inteligência do armazenamento, eliminando aquele ponto único de falha e de gargalo que tira o sono da equipe de TI.
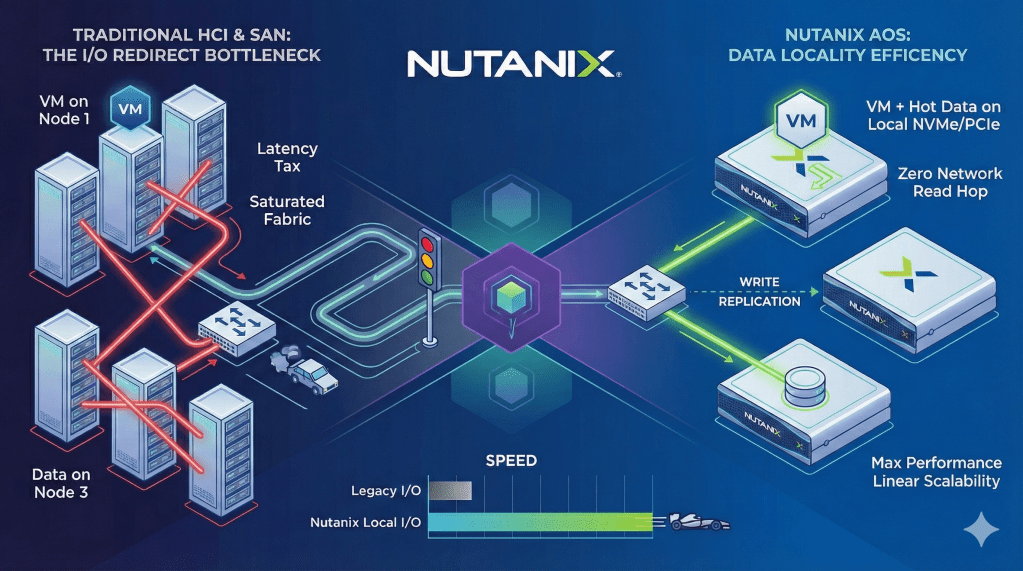
Mas distribuir a inteligência (CVMs) é apenas o começo. Existe um “gargalo invisível” em muitas arquiteturas HCI de mercado que se comportam como um “RAID via Rede”: o I/O Redirecionado.
De que adianta sua VM de Banco de Dados está rodando com CPU e RAM no Node 1, se os blocos de dados que ela precisa ler estão hospedados no disco do Node 3?
Toda vez que isso acontece, você obriga o dado a sair da velocidade do barramento local (NVMe/PCIe), atravessar a placa de rede, cruzar o switch ToR (Top-of-Rack) e voltar. Você está saturando seu fabric de rede com tráfego de leitura que não deveria estar ali. É ineficiência disfarçada de convergência.
Hoje, vamos entender por que garantir que a VM e o Dado morem no mesmo endereço físico (o mesmo Node) é a uma forma de garantir performance linear e estancar o desperdício de recursos.
O Mito da “Rede Infinita”
Existe uma crença perigosa entre arquitetos de infraestrutura: a ideia de que, se a rede for rápida o suficiente (25GbE, 100GbE), a distância entre a CPU e o disco se torna irrelevante.
Durante décadas, construímos múltiplas infraestruturas baseadas em SANs. E sejamos honestos, a tecnologia de storage segregado não parou no tempo. Modelos High-End com NVMe-oF (Over Fabrics) e as arquiteturas customizadas dos grandes Cloud Providers provam que é possível ter performance brutal com storage separado.
O problema é a escala e a complexidade necessárias para fazer isso funcionar sem gargalos.
Enquanto um Hyperscale desenha seu próprio hardware e rede para mitigar a latência, a realidade da maioria dos datacenters corporativos ainda é a topologia clássica de três camadas (Servidor – Switch – Storage). Nesse cenário, insistir na separação física impõe um pedágio desnecessário. Por que forçar o dado a cruzar a rede se, com a densidade atual dos servidores, podemos processá-lo no barramento PCIe local com latência de microssegundos?
A realidade é que largura de banda (throughput) não resolve latência. Você pode ter uma rodovia de dez pistas, mas se o carro precisa viajar 50 km para buscar cada pacote, o tempo de viagem existe. Em arquiteturas tradicionais, toda operação de I/O precisa sair da CPU, atravessar o barramento PCIe, passar pela HBA, cruzar os switches, chegar na controladora do storage, ser processada e só então acessar o disco.
Isso funcionava bem quando o gargalo era o HDD mecânico. Hoje, com NVMe respondendo em microssegundos, a rede se tornou o novo gargalo. Manter essa arquitetura é como colocar um motor de Fórmula 1 em um carro, mas obrigá-lo a parar em todos os semáforos.
A Realidade Técnica: O Caminho do Dado no AOS
A Nutanix ataca esse problema com um princípio de engenharia chamado Data Locality (Localidade de Dados). Diferente de outras soluções de HCI que distribuem os dados aleatoriamente pelo cluster (similares a um RAID via rede), o Nutanix AOS prioriza obsessivamente manter o dado “quente” no mesmo Node físico onde a Máquina Virtual (VM) está rodando.
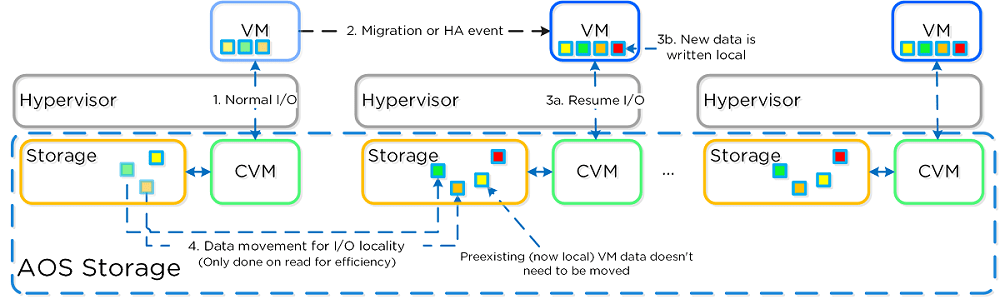
Vamos descer ao nível do daemon. O processo Stargate (responsável pelo I/O de dados) na CVM atua como um guarda de trânsito inteligente:
- Na Escrita (Write): O dado é escrito imediatamente no SSD/NVMe local para garantir performance. Simultaneamente, cópias (Réplicas) são enviadas para outros Nodes do cluster via rede para garantir disponibilidade. O acknowledge de gravação só é devolvido ao SO da VM quando a persistência é confirmada.
- Na Leitura (Read): Aqui reside a mágica financeira. Como o dado foi escrito localmente, quando a VM solicita a leitura, o Stargate busca o bloco diretamente no disco local. Zero tráfego de rede. Não há salto de switch, não há negociação de porta, não há disputa de banda com outros vizinhos.
E se a VM migrar (Live Migration) para outro Node? O sistema entende a mudança. Inicialmente, o Stargate busca os dados remotamente (no Node antigo). Mas, em segundo plano, um processo transparente começa a trazer os dados “quentes” para o novo Node local. Em poucos minutos, a localidade é restaurada e a performance volta ao pico, sem intervenção humana.
A Analogia: O Chef de Cozinha vs Delivery
Imagine um restaurante de alta gastronomia para entender a diferença de latência.
O Modelo Tradicional (SAN): Você tem uma cozinha central gigantesca (Storage Array) do outro lado da cidade. O salão onde os clientes comem (Servidores/Compute) fica no centro. Para cada prato pedido, um motoboy (Fibre Channel) precisa correr até a cozinha, pegar o prato e trazer. Se houver trânsito (congestionamento na rede) ou se a cozinha estiver atolada, seu cliente espera. A comida chega fria. O cliente reclama.
O Modelo Nutanix (Data Locality): O chef (CVM) e os ingredientes (Discos Locais) estão literalmente na frente do cliente (VM). O cliente pede, o chef prepara ali mesmo e serve imediatamente. Não há motoboy para servir o prato. Não há trânsito. O tempo entre o pedido e a entrega é determinado apenas pela velocidade do chef.
O “motoboy” (Rede) ainda existe na Nutanix? Sim, mas ele só é usado para levar uma cópia de segurança para o arquivo morto (Replicação), não para servir o cliente faminto.
Cenário: O Relatório de BI da Black Friday
Vamos aplicar isso onde dói, no bolso.
Imagine um varejista durante a Black Friday. O banco de dados SQL Server que alimenta o e-commerce e os relatórios de BI em tempo real está sob pressão máxima.
No ambiente legado: O storage central está sendo bombardeado por milhares de IOPS de transações de venda. Ao mesmo tempo, a equipe de dados tenta rodar queries pesadas de leitura para gerar dashboards. O link entre os servidores e o storage satura. A latência do disco, que normalmente é de 2ms, salta para 25ms. O site fica lento. O carrinho de compras trava. A diretoria toma decisões baseada em dados atrasados.
Com Data Locality: A VM do SQL Server tem seus dados de leitura (os datafiles) no SSD local do Node onde ela reside. As queries de leitura massiva do BI não saem para a rede, elas são resolvidas internamente no barramento do servidor. O tráfego de rede do cluster fica livre para o que realmente importa, replicar as transações de venda (writes) para garantir a integridade. O resultado não é apenas “rapidez”, é consistência. O tempo de resposta permanece estável porque você eliminou a contenção do link compartilhado.
Financeiramente, isso significa extrair mais performance do mesmo hardware, postergando compras desnecessárias de expansão de rede.
Conclusão Estratégica
A arquitetura de Data Locality não é apenas uma feature técnica; é uma estratégia de eficiência operacional. Ao aproximar o dado da computação, eliminamos camadas de complexidade e pontos de latência que, historicamente, tentávamos resolver colocando dinheiro em equipamentos de rede mais rápidos.
Evoluir para uma arquitetura hiperconvergente com localidade real de dados significa parar de lutar contra a física e começar a usá-la a seu favor. O gargalo deixa de ser a infraestrutura e passa a ser, finalmente, apenas a velocidade do negócio.
Reflexão
Antes de renovar o suporte daquela SAN ou comprar o próximo switch Core, analise friamente:
- Sua latência atual é, na verdade, tempo de espera em filas de rede e controladoras congestionadas?
- Se eliminar o tráfego de leitura (Read I/O) da sua rede, quanto você economizaria em portas de switch e complexidade de fabric?
- Suas aplicações críticas estão lentas por falta de processamento ou porque estão “esperando o motoboy” trazer os dados?
No próximo artigo sobre Nutanix, vamos entrar na matemática da segurança: Fatores de Replicação (RF2 vs RF3).

Leave a comment