No nosso último encontro, falamos sobre o plano de controle da Nutanix, isolando as responsabilidades de governança global do Prism Central e a autonomia de execução local do Prism Element. Com a gerência e o processamento consolidados, a próxima camada crítica para garantir a sustentação do datacenter é a conectividade. Em topologias tradicionais de virtualização, a rede costuma ser uma das áreas de maior atrito operacional, exigindo a configuração manual e descentralizada de switches lógicos distribuídos, o que eleva a complexidade e a margem para falhas ocultas.
Para mitigar esses gargalos de comunicação sem introduzir novos pontos de falha, a estrutura do Nutanix AHV abstrai a camada de conectividade através do Open vSwitch (OVS). Executado de forma nativa e integrada ao kernel do hypervisor, esse comutador virtual de código aberto transfere a responsabilidade da equipe de TI do microgerenciamento de portas físicas para a orquestração de fluxos lógicos e políticas de tráfego.
O objetivo deste artigo é analisar a engenharia por trás dessa entrega: como o Open vSwitch organiza o isolamento de rede nativo entre os componentes do cluster, de que forma os diferentes algoritmos de agregação de interfaces (Bonds) otimizam o escoamento de dados para a rede física e como o gerenciamento automatizado de endereços reduz o tempo de provisionamento de novos ambientes.
A Fundação Técnica: Open vSwitch e a Estrutura de Bonds
No AHV, a espinha dorsal da rede é o Open vSwitch. O tráfego não flui de forma desordenada; ele é segmentado em pontes lógicas (bridges) com funções rigorosas de isolamento.
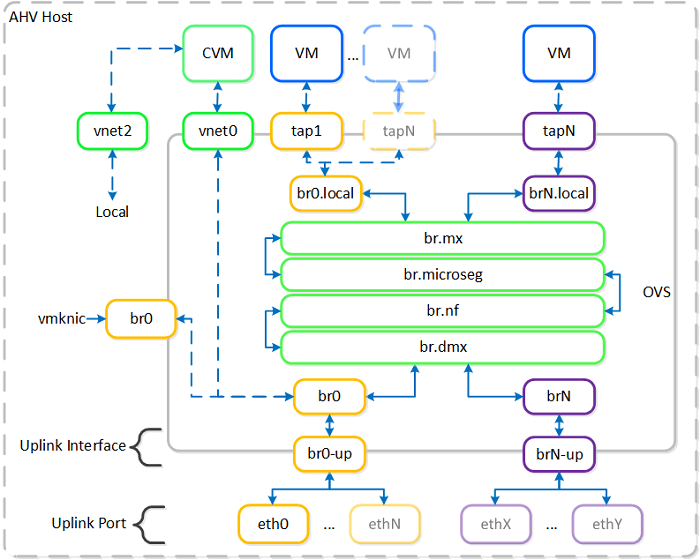
A comunicação interna entre a CVM (Controller VM) e o hypervisor ocorre através de uma ponte dedicada chamada br0.local (anteriormente nomeada virbr0 em versões passadas, mantendo a padronização do diagrama), rodando em uma sub-rede interna isolada 192.168.5.0/24. Isso garante que o tráfego crítico de armazenamento local nunca concorra diretamente com a rede de produção das aplicações.
Para o mundo externo, o OVS utiliza a ponte br0 (bridge zero). Ela atua como o comutador central do nó, conectando as interfaces virtuais das máquinas (vNICs) à rede física. A conexão de saída da br0 com os cabos físicos ocorre através de uma interface lógica de agregação nomeada br0-up.
A porta br0-up é exatamente o Bond que agrupa as placas de rede do servidor. A escolha do algoritmo desse Bond define o comportamento de escoamento de dados e a necessidade de interação com os switches Top of Rack:
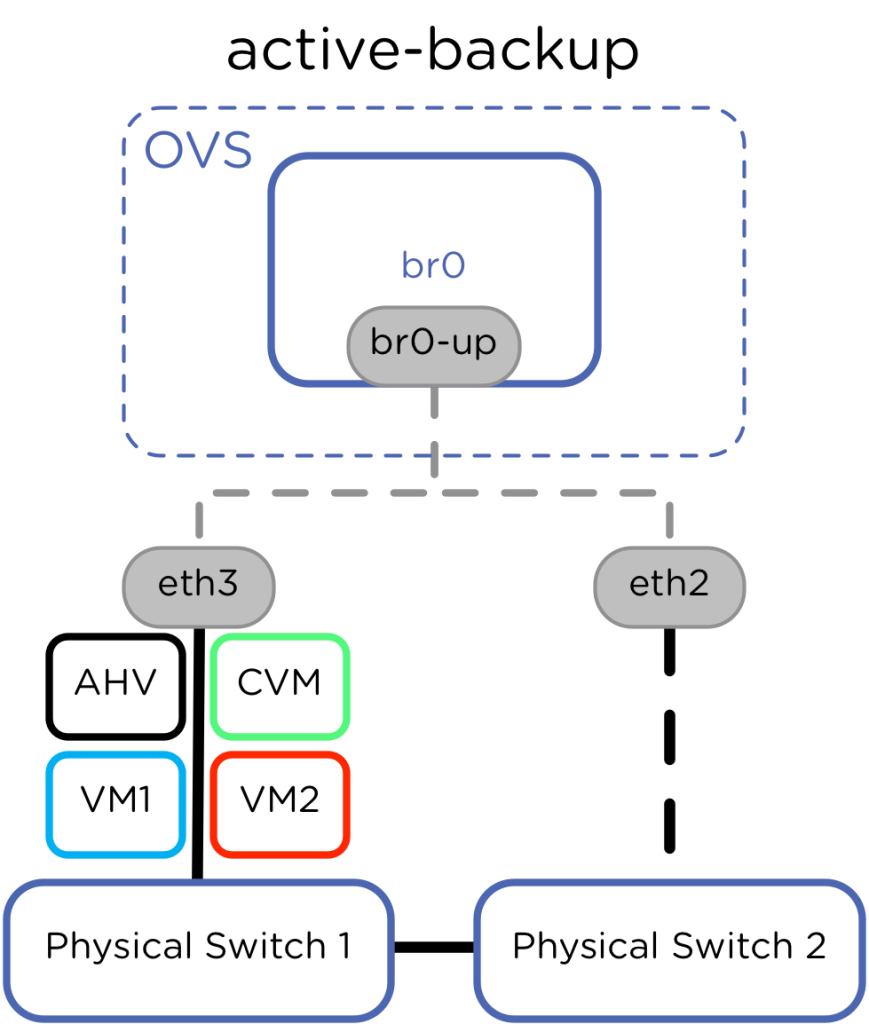
- Active-Backup: É a configuração nativa e o padrão para a maioria dos cenários. Uma única interface física do Bond assume todo o tráfego de saída do nó, enquanto as demais interfaces permanecem em estado de espera. Se a porta ativa, o cabo ou o switch upstream falharem, o OVS transfere o fluxo imediatamente para a interface de backup através de um Gratuitous ARP. A vantagem técnica desse modelo é a simplicidade operacional, pois funciona de forma totalmente independente e não exige configuração de agregação ou protocolos nos switches físicos. Além disso, por operar em failover puro, elimina riscos de loops de rede ou problemas com tráfego multicast e broadcast na camada física, tornando-se a opção mais estável para isolar o tráfego de gerência e produção.camada física, tornando-se a opção mais estável para isolar o tráfego de gerência e produção.
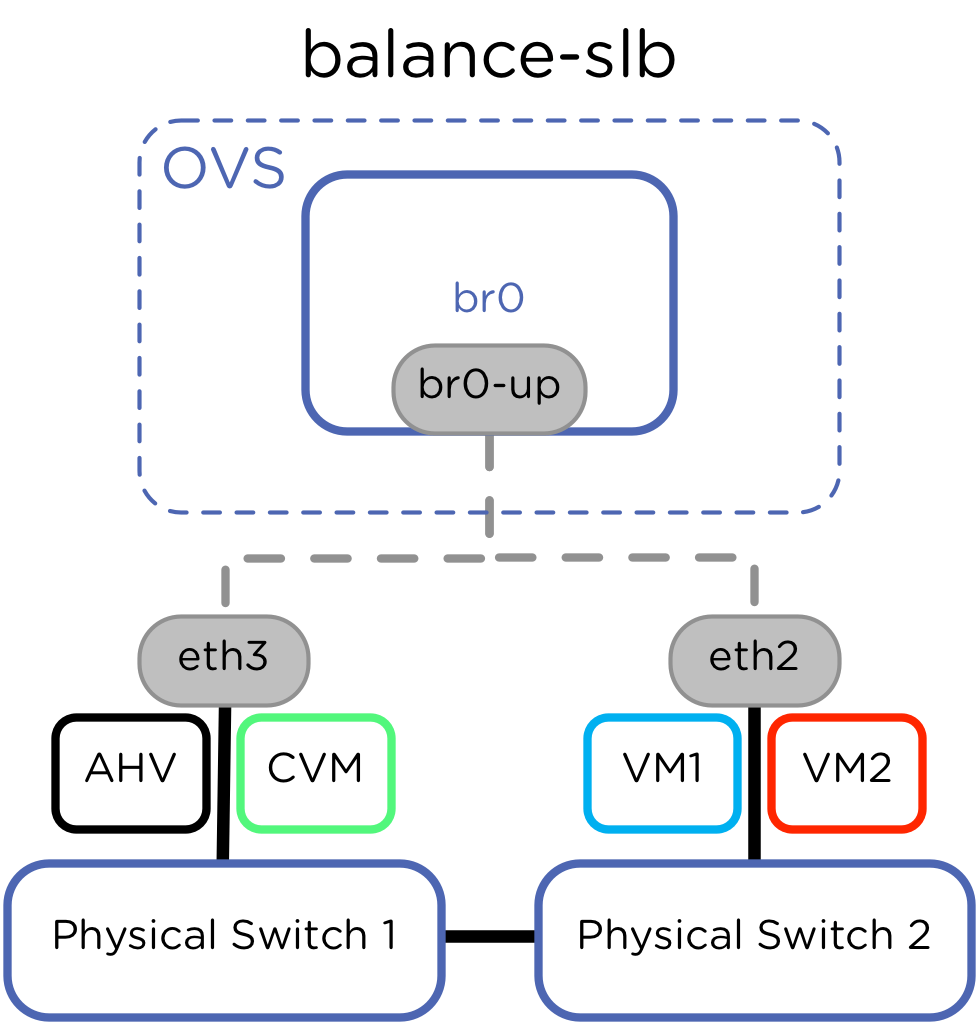
- Balance-SLB (Source Load Balancing): Ativa o balanceamento de carga ativo-ativo sem exigir suporte a agregação nos switches do datacenter. O OVS distribui o tráfego de saída utilizando um hash do endereço MAC de origem da máquina virtual, monitorando a carga das interfaces físicas para remanejar os fluxos periodicamente caso identifique saturação em um dos links. A ressalva técnica deste modelo está na forma como ele lida com o tráfego que entra no host. Como não há comunicação de protocolo com a rede física, o switch upstream não identifica o agregado e encaminha o tráfego por caminhos baseados em seu próprio aprendizado de MAC. Se a infraestrutura de switches não estiver com o recurso de IGMP snooping ativo, fluxos multicast podem gerar duplicação de pacotes e descarte indevido nas vNICs das máquinas virtuais.
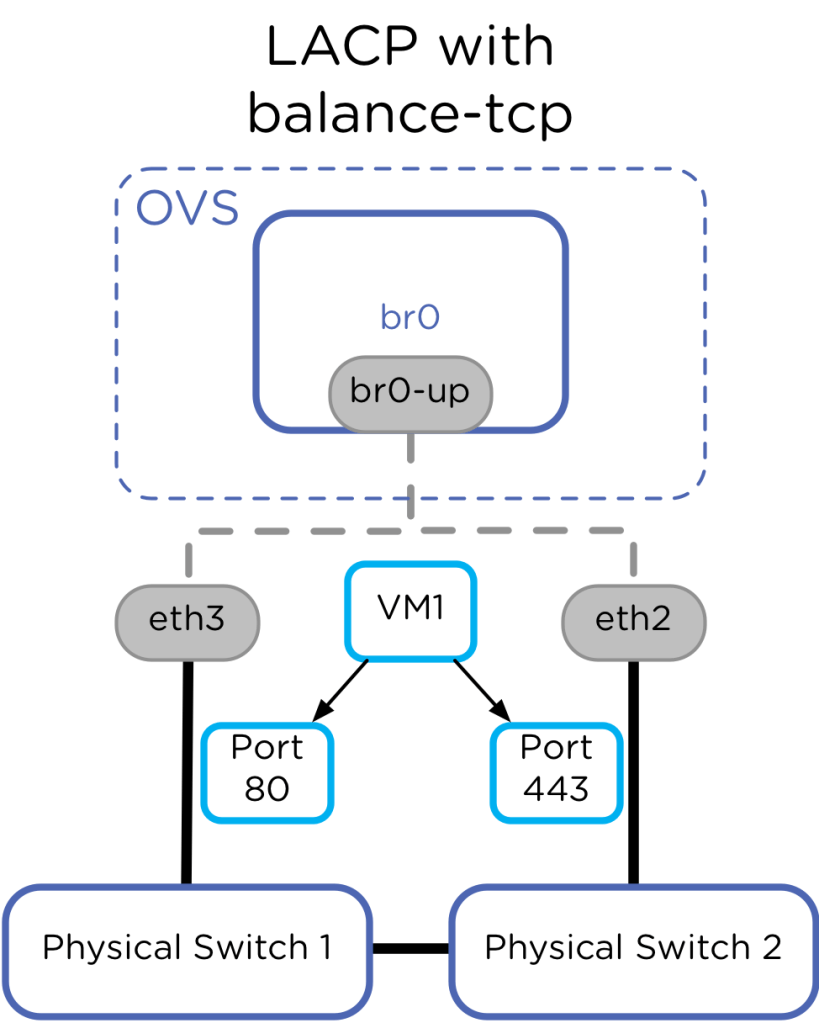
- Balance-TCP (LACP): Modelo focado na extração de performance e resiliência de throughput. Ele exige que os switches físicos estejam agrupados (via MLAG/vPC) e configurados com o protocolo LACP (padrão 802.3ad). O OVS distribui o tráfego de saída de forma granular utilizando um hash combinado de camada 2, 3 e 4 (endereços MAC, IPs e portas TCP/UDP). Isso permite que fluxos de dados distintos vindos de uma única máquina virtual de alta demanda utilizem múltiplos links físicos simultaneamente. A premissa técnica deste modelo está na segurança do plano de controle de rede durante falhas. Se o switch físico perder a configuração de LACP ou passar por uma reinicialização, o OVS precisa estar configurado com o parâmetro de fallback ativo (lacp-fallback=true). Sem essa diretiva, a perda do sincronismo do protocolo faz com que as interfaces físicas do host parem de encaminhar pacotes completamente, isolando o nó e o cluster da rede física.
Segmentação de Tráfego: VLANs no Host e na CVM
A configuração de VLANs no ecossistema Nutanix segue uma premissa de isolamento e segurança. Por padrão, tanto os hosts AHV quanto as CVMs são implantados sem tags de VLAN na interface principal, operando na VLAN nativa da infraestrutura física corporativa.
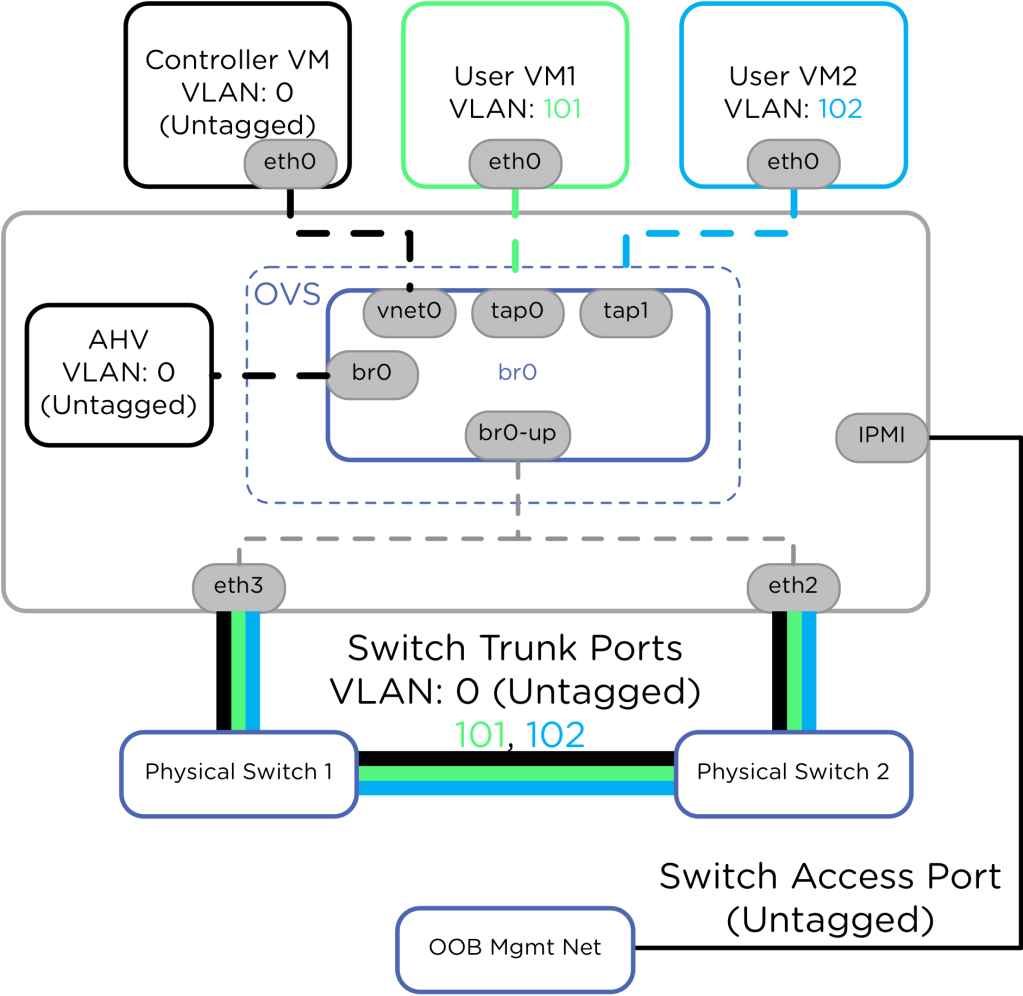
Mudar essa estrutura nativa para atender a políticas específicas de conformidade ou segregação de redes exige precisão técnica tanto na camada física de switches quanto no plano de controle:
- VLAN da CVM e do Host: É recomendado manter a CVM e o seu respectivo host AHV na mesma sub-rede e sob a mesma tag de VLAN de gerência. Quando o tráfego de gerenciamento precisa ser isolado do restante da rede, a alteração deve ser aplicada simultaneamente no nó e na CVM. Isolar a CVM em uma VLAN diferente do seu hypervisor local adiciona saltos de roteamento e latência desnecessária no plano de controle de armazenamento, podendo impactar a comunicação do cluster.
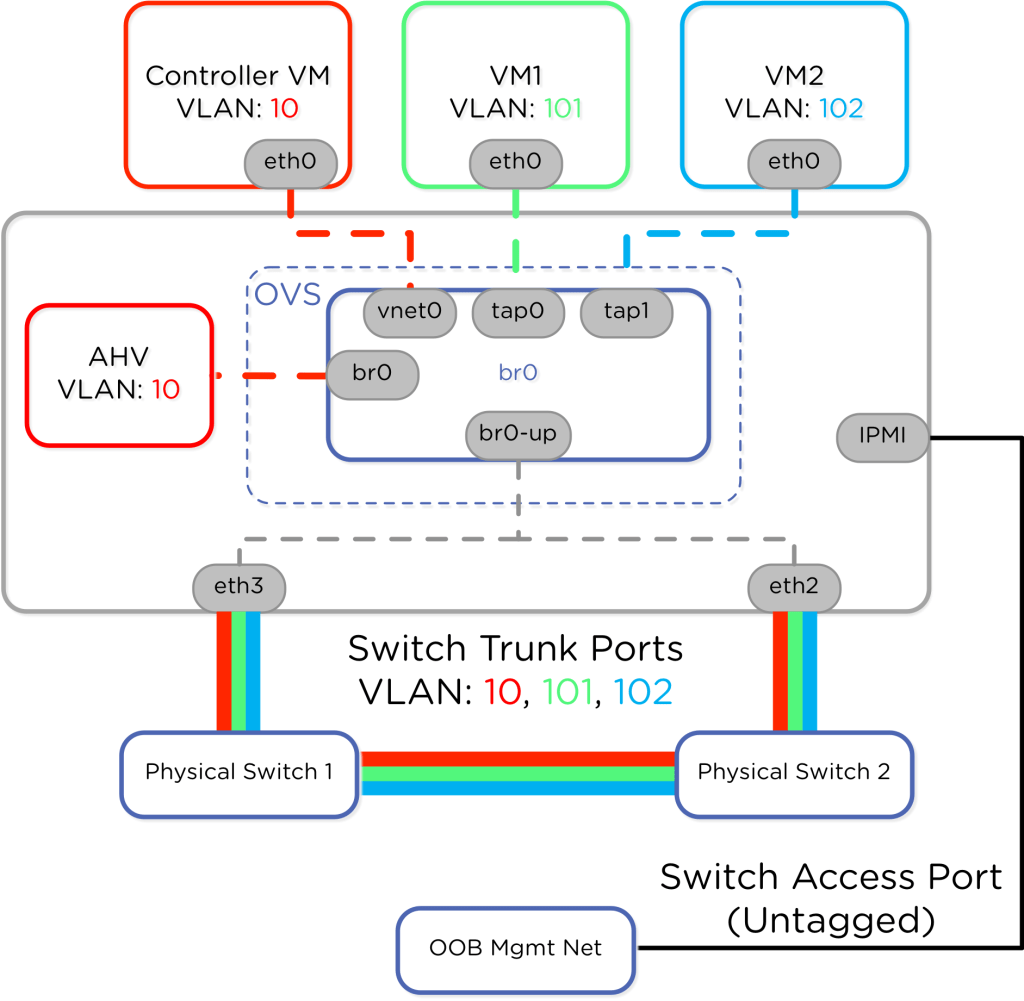
- Tráfego de Produção (Aplicações): As redes das máquinas virtuais operam de forma independente da gerência do cluster. O Open vSwitch (OVS) realiza a marcação de pacotes (802.1Q VLAN tagging) diretamente nas portas virtuais (vNICs) antes que o fluxo de dados saia pelo Bond br0-up. Para que essa segmentação funcione na prática, as portas correspondentes nos switches físicos (Top of Rack) devem ser configuradas obrigatoriamente em modo Trunk, permitindo a passagem das tags de VLAN definidas no painel do AHV.
A estabilidade da infraestrutura distribuída depende dessa organização. Misturar o fluxo de dados das aplicações de produção com o tráfego de sincronismo de storage da CVM ou com a gerência os hosts prejudica a previsibilidade da rede e expõe o ambiente a gargalos de performance.
Gerenciamento de Endereçamento: Redes Gerenciadas e o IPAM
O gerenciamento de endereçamento IP é um fator frequente de atrito na entrega de novos serviços. Para mitigar a dependência de serviços externos de infraestrutura, o AHV divide o provisionamento de redes virtuais em dois modelos operacionais bem definidos:
- Redes Não Gerenciadas: O hypervisor atua estritamente como uma ponte de camada 2. O Open vSwitch encaminha os pacotes diretamente para a rede física, repassando a responsabilidade de resolução, alocação e gerenciamento de endereços IP para servidores DHCP externos já existentes na infraestrutura ou para políticas de configuração estática dentro de cada sistema operacional.
- Redes Gerenciadas: O AHV assume nativamente a função de IPAM (IP Address Management). Nesse modelo, o hypervisor utiliza regras internas do OVS para interceptar as solicitações DHCP das máquinas virtuais e responder diretamente com os endereços IPs alocados a partir de um pool configurado. O sistema gerencia de forma dinâmica a atribuição de IPs, máscaras de rede, gateways e servidores DNS para as portas virtuais lógicas das VMs.
Essa estrutura elimina a necessidade de coordenação de serviços externos e roteamentos complexos para o provisionamento básico de rede. A equipe de TI ganha a capacidade de criar, isolar e destruir sub-redes inteiras diretamente pelo painel de controle, garantindo consistência no endereçamento e velocidade na automação de novos ambientes.
A Analogia: O Supermercado e a Distribuição de Fluxos
Para entender como o AHV gerencia o tráfego de dados, o isolamento de segurança e a entrega de endereços de forma nativa, podemos observar a dinâmica de funcionamento de um grande supermercado em um dia de movimento. O sucesso dessa operação depende de como os clientes e suas compras são distribuídos entre os diferentes modelos de caixas de pagamento.
O primeiro ponto de eficiência está nos caixas de autoatendimento, o conhecido self-checkout. Neles, o cliente não precisa pegar filas externas ou aguardar que um funcionário valide a sua entrada e registre os produtos, resolvendo todo o processo de identificação e fechamento de forma autônoma no próprio terminal. Na arquitetura do AHV, esse modelo representa as redes gerenciadas pelo IPAM nativo, onde a máquina virtual recebe todas as suas configurações de rede diretamente do hypervisor, eliminando o tempo de espera e a dependência de servidores externos para o provisionamento básico.
Logo ao lado, temos os caixas tradicionais de alta capacidade, que operam como as esteiras largas posicionadas em paralelo para escoar o tráfego pesado de carrinhos cheios. A operação distribui os clientes de forma equilibrada entre os operadores ativos para maximizar a velocidade de saída e evitar gargalos. Se uma dessas esteiras apresentar defeito, o fluxo de clientes é redirecionado imediatamente para os outros caixas abertos, garantindo a continuidade do processo. Essa é a mecânica da ponte principal do cluster rodando em modo de agregação com links de alta capacidade, onde o Open vSwitch distribui os pacotes por múltiplas interfaces físicas de forma simultânea para extrair a performance máxima e garantir resiliência para a produção geral.
Por fim, a estrutura conta com os caixas exclusivos ou preferenciais, que funcionam de maneira isolada do restante do estabelecimento. Trata-se de uma linha física de atendimento totalmente separada, com uma esteira que não pode ser compartilhada com as compras do público geral. Esse isolamento garante um tempo de resposta previsível e sem interferências para um perfil específico de cliente. No ambiente do hypervisor, essa configuração reflete a ponte secundária em modo de failover puro, uma rodovia exclusiva e dedicada para um pool de serviços críticos onde os dados correm de forma linear por um único caminho físico por vez, sem risco de disputa de banda com o restante das máquinas virtuais do datacenter.
O Cenário: Alta Performance e Isolamento Físico
Considere a implantação de um novo cluster composto por 4 nós, onde cada nó dispõe de 6 interfaces físicas de rede operando a 25 Gbps. A equipe de TI deve seguir duas diretrizes para o provisionamento do ambiente:
- Toda a infraestrutura deve suportar MTU em 9000 (Jumbo Frames), garantindo que tanto o tráfego do hypervisor quanto o das máquinas virtuais trafeguem sem fragmentação de pacotes para extrair o desempenho máximo dos links.
- Um pool específico de máquinas virtuais, responsáveis por um serviço crítico de baixa latência, deve operar com interfaces físicas totalmente dedicadas, proibindo que qualquer outra carga de trabalho do cluster compartilhe essas placas, impedindo que o tráfego desse sistema saia por múltiplas interfaces físicas de forma simultânea.
Para cumprir a primeira diretriz de performance máxima combinada com resiliência, a equipe de TI implementa o modo Balance-TCP (LACP) nas quatro primeiras interfaces de 25 Gbps, agrupando-as na ponte padrão br0. Esse arranjo permite que o OVS distribua os fluxos de dados utilizando o hash completo de portas e IPs, maximizando o throughput agregado do cluster para 100 Gbps. Para habilitar o Jumbo Frames, a configuração do MTU em 9000 é aplicada nos switches físicos ToR e na ponte lógica br0 do host AHV.
Com essa fundação ajustada no AHV, o suporte a pacotes maiores torna-se transparente para as Guest VMs, que passam a trafegar dados em alta capacidade sem risco de descarte. Caso uma Guest VM envie pacotes no padrão de 1500 bytes, a ponte em 9000 recebe o fluxo de forma nativa e sem necessidade de fragmentação, operando com compatibilidade.
Como premissa de estabilidade e seguindo as recomendações oficiais do fabricante, a equipe de TI mantém o MTU das CVMs (Controller VMs) em 1500 bytes. O OVS gerencia essa coexistência isolando o tráfego de controle e armazenamento local na ponte interna virbr0. Quando a CVM precisa se comunicar externamente com os outros nós, os pacotes de 1500 bytes são injetados na ponte br0 de 9000 de forma transparente, sem gerar alertas no cluster ou overhead de processamento.
Para resolver a segunda diretriz de isolamento total e restrição de dispersão de tráfego do serviço crítico, a equipe de TI cria uma segunda ponte lógica no OVS, nomeada como br1, definindo também o seu MTU em 9000. As duas interfaces de 25 Gbps restantes de cada nó são removidas da estrutura padrão e vinculadas exclusivamente como uplinks da br1 através de um Bond configurado em modo Active-Backup.
Essa escolha é mandatória, pois o modelo de failover puro garante que apenas uma interface física transmita os dados por vez, impedindo que os pacotes sejam divididos ou roteados simultaneamente pelos dois links físicos, o que ocorreria caso fosse utilizado um modo baseado em hash. Ao provisionar as máquinas virtuais do pool de serviço crítico, a equipe de TI associa suas vNICs diretamente à nova rede vinculada à br1. Essa separação no nível de kernel do OVS garante o isolamento físico e a previsibilidade de rota exigidos pelo negócio. Como o tráfego da br1 possui placas de rede dedicadas, switches virtuais independentes e um caminho físico linear, os pacotes desse serviço crítico correm em uma rodovia exclusiva, sem risco de disputa de banda com as demais aplicações.
Conclusão Estratégica
A maturidade de uma infraestrutura de TI é medida pela velocidade e segurança com que ela sustenta as operações da empresa. Quando a camada de redes deixa de ser um ecossistema isolado de microgerenciamento físico e passa a ser uma camada lógica integrada ao hypervisor, o impacto direto reflete-se na eficiência operacional e financeira.
Do ponto de vista de eficiência, a automação e a consolidação de recursos no Open vSwitch mudam o ritmo de entrega do negócio. Reduzir o tempo de provisionamento de novas sub-redes e eliminar a dependência de intervenções manuais na infraestrutura de switches significa acelerar o time-to-market. Projetos internos, novos serviços digitais e plataformas de atendimento chegam ao ambiente de produção em fração de horas, e não de dias, removendo o atrito entre as frentes de desenvolvimento e sustentação.
Sob a ótica de continuidade de negócios, o desenho de uma rede resiliente e previsível atua diretamente na mitigação de riscos financeiros causados por indisponibilidade. Garantir o escoamento de alta performance em links agregados, sem fragmentação de pacotes, ao mesmo tempo em que se isola fisicamente os serviços críticos em rodovias exclusivas, protege a operação contra falhas humanas ou de hardware. O resultado prático para o negócio é a otimização dos custos operacionais (OPEX) e a proteção do capital investido (CAPEX), permitindo extrair o potencial máximo do hardware de conectividade já adquirido diretamente a partir do kernel.
Reflexão
- A sua infraestrutura atual de rede consegue extrair e distribuir o throughput máximo de links de alta capacidade, como 25 ou 100 Gbps, de forma nativa, ou a entrega de performance ainda esbarra em limitações de balanceamento e configurações complexas nos switches físicos?
- Sempre que uma nova sub-rede ou ambiente de testes precisa ser criado, a equipe de TI depende da abertura de chamados, gerenciamento manual de IPs e intervenções em ativos de rede externos, gerando atrito e atrasos no provisionamento?
- O desenho de conectividade do seu datacenter atual permite o isolamento físico de serviços críticos em caminhos exclusivos com a mesma simplicidade que gerencia as redes comuns, ou a segregação de hardware ainda exige uma reestruturação completa da topologia lógica?

Leave a comment