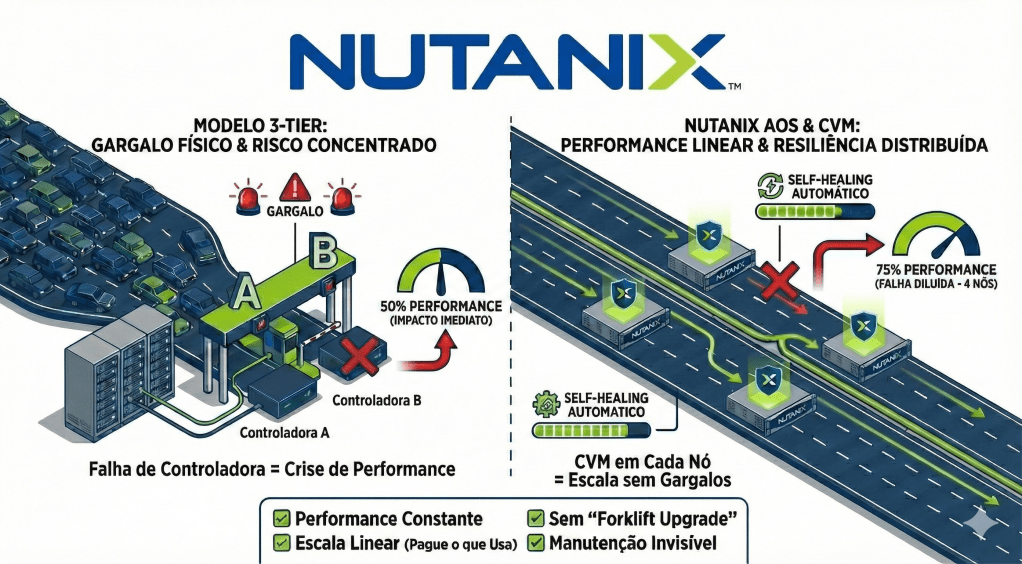
Imagine uma rodovia com dez pistas (seus servidores) que, de repente, se afunila em um pedágio com apenas duas cabines (seu Storage Array). Não importa a potência dos veículos, sejam VMs, Containers, Bancos de Dados ou Servidores de Arquivos, nem quão larga seja a estrada: a velocidade total de todos os seus workloads será sempre ditada pela capacidade dessas duas cabines de processar o tráfego.
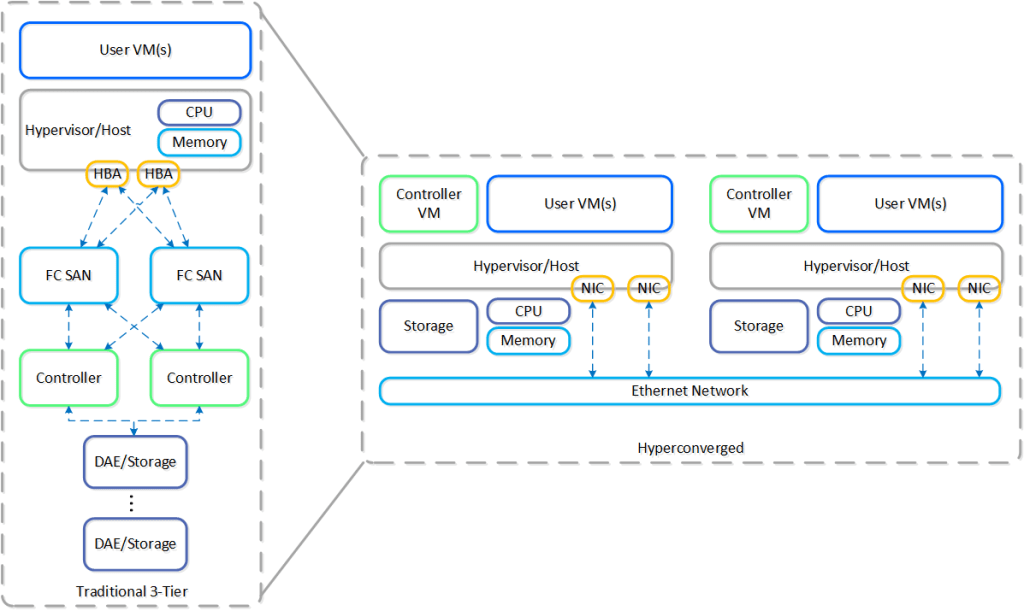
Essa é a realidade da arquitetura 3-tier. Por décadas, confiamos o coração do datacenter a grandes arrays de armazenamento centralizados e proprietários, operando com apenas duas controladoras (Active-Active ou Active-Passive). É um design que cria, por definição, um gargalo físico e um ponto crítico de falha. Se você perde uma controladora, perde 50% da performance instantaneamente. Se perde o backplane ou sofre uma corrupção de firmware em ambas, o “apagão” é total.
Entra em Cena a CVM (Controller VM)
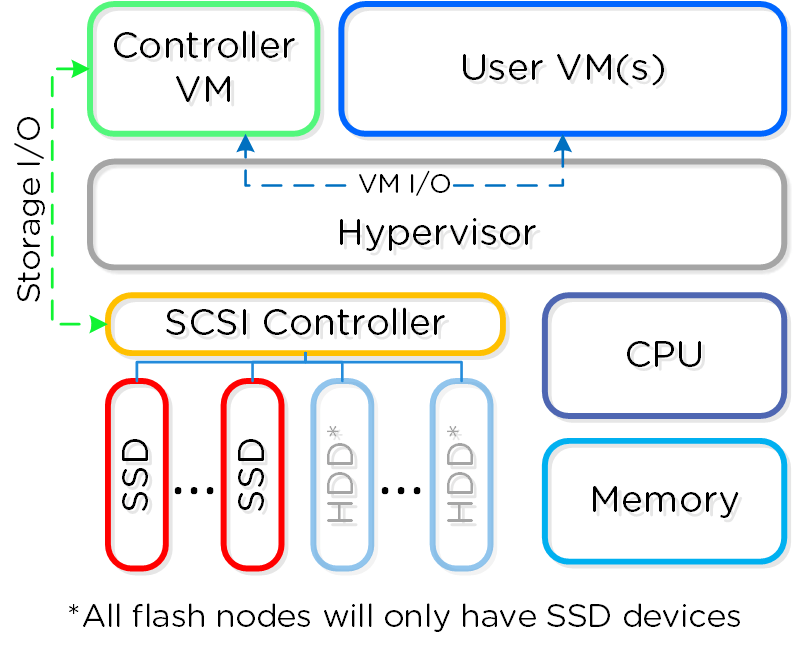
A Nutanix inverte essa lógica de arquitetura. O fundamento do AOS (Acropolis Operating System) é eliminar o hardware dedicado de controle e virtualizá-lo.
Aqui nasce a CVM (Controller VM). Em vez de concentrar toda a lógica de escrita e leitura em apenas duas controladoras físicas centralizadas, a Nutanix distribui essa responsabilidade, colocando um “controlador de software” rodando em cada servidor do cluster.
A CVM não é uma máquina virtual comum, ela é uma appliance de sistema que tem acesso direto (via PCI Passthrough) aos discos físicos daquele servidor (NVMe, SSD, HDD). Ela assume o papel que antigamente pertencia à controladora do Storage, mas com uma diferença crucial: ela trabalha em time.
Shared Nothing: A Democracia da Infraestrutura
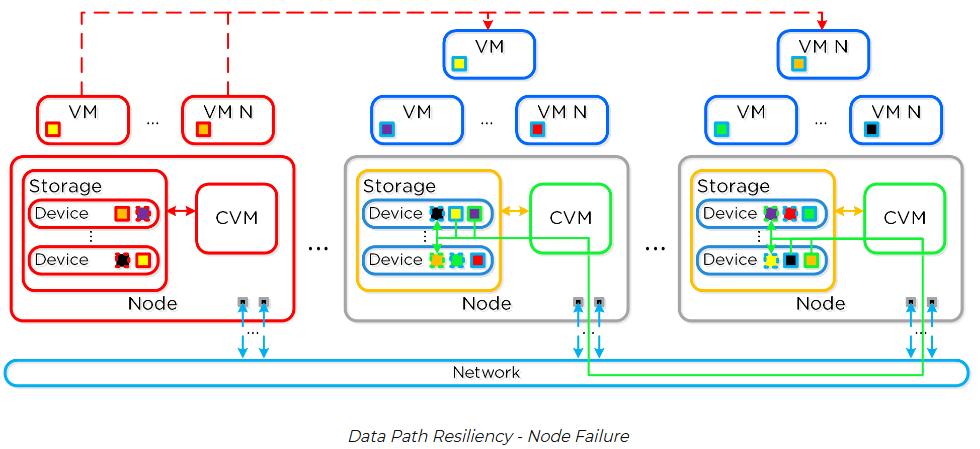
Em um cluster Nutanix, não existe um “nó mestre” que, se morrer, derruba o cluster. Isso é o que chamamos de arquitetura Shared Nothing.
Todas as CVMs conversam entre si para formar um único pool de armazenamento distribuído, mas nenhuma delas é insubstituível. Trazendo para um cenário real: se você tem um cluster de 4 nós, você tem “4 controladores de storage” trabalhando em paralelo. Se um servidor falha, os outros 3 continuam operando normalmente, assumindo a carga.
A matemática é simples e brutal. Enquanto no modelo 3-tier a falha de uma controladora compromete 50% da sua performance (porque você só tem duas), com Nutanix, perder um nó nesse cenário significa um impacto de apenas 25%. Quanto mais seu cluster cresce, menor é esse risco. É a diluição do problema através do software.
A Matemática da Escala Linear: Adeus à “Curva do Gargalo”
No modelo 3-tier, fazer um upgrade de capacidade é, muitas vezes, um “tiro no pé” da performance. Pense no cenário clássico: você comprou um Storage Array com duas controladoras e 50TB de disco. Dois anos depois, o espaço acabou. Você compra mais gavetas de disco (Expansão de Shelf) e pluga na mesma controladora antiga.
O resultado? Você tem mais dados para gerenciar, mas o mesmo “cérebro” para processar tudo. O IOPS por GB cai, a latência sobe e o gargalo piora. É a lei dos retornos decrescentes.
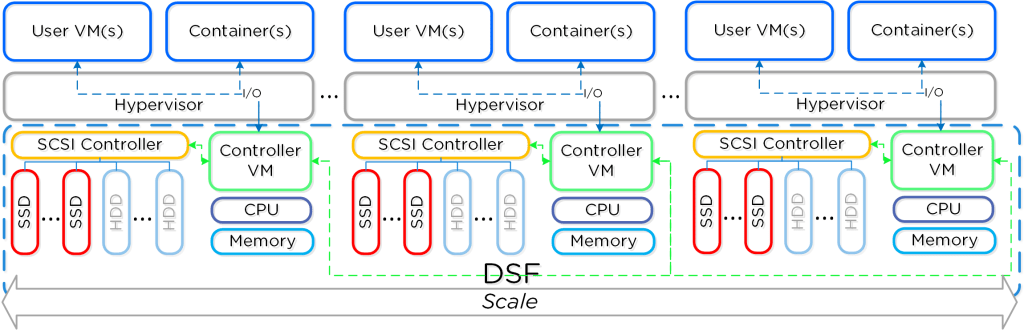
Com a arquitetura da CVM, a lógica muda.
Quando você expande seu cluster de 4 servidores (indo para 5, por exemplo), você não está adicionando apenas disco e memória. Você está adicionando novas controladoras de storage (CVMs) e mais processamento dedicado exclusivamente para I/O.
Isso gera o que chamamos de Performance Linear:
- 4 Nós = 4x Performance de Storage.
- 5 Nós = 5x Performance de Storage.
O cluster não fica mais lento à medida que cresce, ele fica mais potente. Você elimina a necessidade daquele planejamento de capacidade “bola de cristal” para tentar adivinhar quanto de CPU de storage vai precisar daqui a 5 anos. Você cresce conforme a demanda, pagando apenas pelo que usa hoje, sabendo que a performance de amanhã está garantida na arquitetura.
Gestão de Risco: A Matemática da Diluição de Falhas
Aqui entramos no território que tira o sono dos gestores de TI: o impacto de uma falha.
Na arquitetura 3-tier (Dual Controller), o risco é concentrado. Se uma das controladoras falhar, você perde instantaneamente 50% da sua capacidade de processamento de dados. Pior, em muitos storage arrays, a perda de uma controladora força o sistema a desativar o Write Cache para proteger os dados, derrubando a performance para níveis quase inutilizáveis. Uma falha de hardware vira, imediatamente, uma crise de performance que impacta o negócio.
No mundo Nutanix, aplicamos o conceito de diluição de risco. Como cada nó contribui com uma fatia do controle, a perda de um servidor tem um impacto fracionado.
- Em um cluster de 5 nós, perder um servidor significa perder apenas 20% dos recursos. O cluster continua operando com 80% da sua força total.
- Mesmo no cenário inicial de 4 nós, a perda representa apenas 25%, mantendo a grande maioria da capacidade intacta.
Isso acontece porque, assumindo o padrão de mercado RF2 (Redundancy Factor 2), o sistema mantém sempre duas cópias dos dados espalhadas pelo cluster. A grande diferença não é apenas que “continua funcionando”, mas como o sistema reage. Enquanto no modelo tradicional você corre contra o relógio para trocar a peça defeituosa, o AOS inicia um processo de Self-Healing automático. Ele recria as cópias dos dados perdidos nos nós sobreviventes, restaurando a redundância completa do cluster antes mesmo de você trocar o hardware físico.
Transformamos uma emergência na madrugada em um ticket de troca de peça agendado para o horário comercial.
Manutenção Invisível
Por fim, uma vantagem operacional que vale ouro: o fim do medo de atualizar Storage. Quem gerencia infraestrutura tradicional sabe que atualizar firmware de controladora é um evento crítico, que exige janelas na madrugada.
Como a CVM é software, a atualização do cluster ocorre em modo “rolling” um nó de cada vez, sem interromper o serviço. O sistema move os dados, atualiza e reinicia o nó automaticamente, permitindo que você mantenha o ambiente seguro e na última versão operando em horário comercial. Sem heroísmo, apenas processo.
Conclusão: Quando a Arquitetura Vira Estratégia de Negócio
A transição para um modelo definido por software não é apenas um capricho de engenharia, é uma reorientação estratégica do capital. Ao eliminar o gargalo físico das controladoras duplas, a Nutanix permite que o investimento em TI deixe de ser uma aposta especulativa, onde se paga caro hoje tentando adivinhar a demanda dos próximos cinco anos, para se tornar um fluxo previsível.
Isso impacta diretamente o TCO. O modelo de Shared Nothing transforma o CAPEX em uma curva suave, onde a infraestrutura cresce no mesmo ritmo da receita do negócio, eliminando o ciclo vicioso de “Forklift Upgrade” (trocar tudo) apenas para ganhar performance.
Reflexão
Para encerrar, convido você a fazer uma rápida reflexão sobre sua infraestrutura atual:
- Se uma das suas controladoras de storage falhar agora, sua performance continua 100% idêntica ou seus usuários vão sentir lentidão imediata?
- Se você precisar crescer seu ambiente em 50% hoje, como isso funciona? Você precisa comprar mais servidores e uma nova storage? Ou tem a flexibilidade de adicionar apenas nós, expandindo “a quente”?
- Se você adicionar mais dados ao seu storage atual, ele fica mais lento (controladora sobrecarregada) ou mais rápido (mais processamento junto com o dado)?
No próximo post sobre Nutanix, vamos falar sobre Data Locality. Entender por que buscar o dado através da rede (como uma SAN faz) é coisa do passado e como a Nutanix garante que o dado esteja fisicamente no mesmo servidor que a sua aplicação.
Spoiler: Performance constante também é ativo financeiro.

Leave a comment