A infraestrutura da maioria dos datacenters corporativos ainda opera sobre o RAID tradicional (RAID 5, 6, 10). E há um motivo técnico irrefutável para isso, as controladoras em hardware entregam estabilidade e previsibilidade. Elas resolvem de forma eficiente o problema de agrupar drives físicos para somar capacidade, protegendo o volume caso um ou dois componentes falhem. A engenharia do RAID foi desenhada com um propósito primário: proteger o disco e os dados.
O problema prático que costuma passar despercebido no dia a dia da operação é o rebuild. Na realidade dos datacenters (no Brasil), raramente há orçamento sobrando para manter discos apenas como hot spare. Quando você perde um disco de 16TB, normalmente você aciona o suporte, aguarda o SLA da peça, faz a troca física e só então a controladora inicia a reconstrução.
O painel do storage pode até parar de mostrar o alerta vermelho, passando a sensação de que o incidente está resolvido. A realidade é que o processo para calcular a paridade e preencher esse disco novo vai rodar em background por dias, punindo a performance toda do array. Você tem a impressão de que está tudo “OK”, mas a reconstrução está longe de terminar.
Dependendo do nível de RAID, se um segundo disco apresentar falha ou um simples erro de leitura (URE – Unrecoverable Read Error) durante essa longa janela de reconstrução, pode acontecer a inviabilização completa do array inteiro. É um risco de negócio altíssimo, que infelizmente passa despercebido por várias equipes de TI.
A Realidade Técnica: Replication Factor (RF), Metadados e Domínios de Falha
Na arquitetura Nutanix, a proteção de dados abandona a matemática de paridade focada em discos e adota o conceito de Replication Factor (RF), operando estritamente via software através da rede do cluster. O cálculo de paridade tradicional em hardware consome ciclos de CPU dedicados e cria gargalos físicos. O RF distribui a carga.
A regra de I/O é “simples”, quando a VM envia um comando de gravação, o Stargate intercepta a requisição e escreve o bloco imediatamente no Oplog (um buffer persistente e ultrarrápido alocado nos discos NVMe/SSD) do Node local. Simultaneamente, ele dispara essa mesma cópia pela rede para o Oplog de um ou dois Nodes secundários (dependendo da sua configuração de RF).
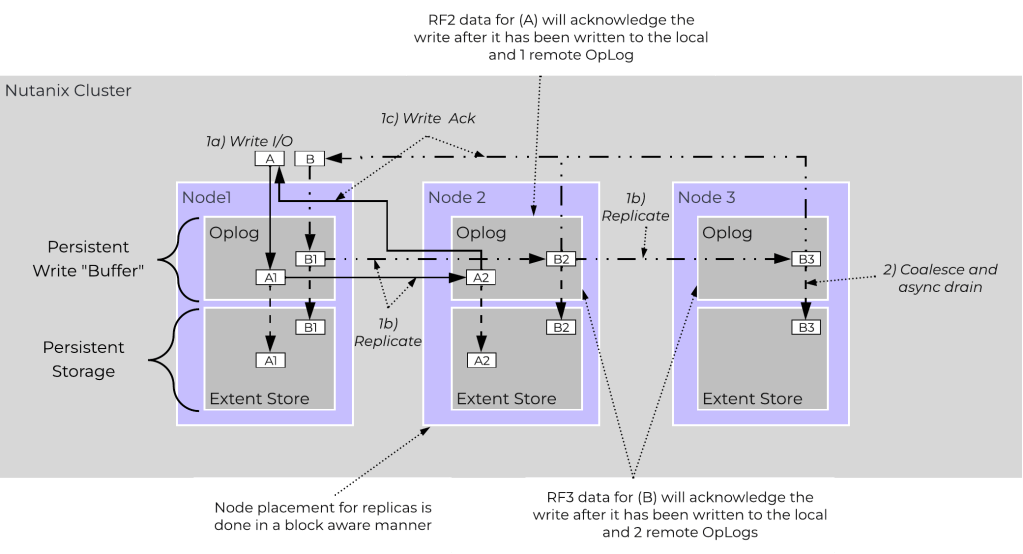
O Acknowledge (Ack) de gravação bem-sucedida só é devolvido ao Sistema Operacional da VM quando os Oplogs de todos os Nodes envolvidos confirmam a persistência física do bloco. Ou seja, o commit da escrita exige redundância. Ou o dado já nasceu protegido em múltiplos hardwares independentes, ou a gravação simplesmente não é confirmada para a aplicação. (Nota técnica: o processo de drenar esses dados do Oplog para a camada de armazenamento massivo, o Extent Store, ocorre posteriormente, de forma assíncrona, sem penalizar a latência da VM).
- RF2 e a Evolução do AOS 7.0: A arquitetura mantém 2 cópias completas dos blocos de dados e 3 cópias dos metadados. Historicamente, isso entrega a resiliência padrão de 1N/1D, onde o cluster tolera a perda integral de 1 Node ou 1 disco. No entanto, se o seu ambiente já roda o AOS 7.0, a engenharia da Nutanix introduziu a arquitetura 1N&1D (1 Node AND 1 Disk). Ao configurar o cluster neste nível, o algoritmo se torna capaz de suportar a falha simultânea de um Node inteiro e mais um disco em um Node sobrevivente. É um salto de resiliência de software que entrega mais segurança que o RF2 legado, sem exigir o overhead de espaço de um ambiente de missão crítica.
- RF3 (Tolerância 2N/2D): O sistema mantém 3 cópias completas dos blocos de dados e 5 cópias dos metadados. O cluster tolera a perda simultânea de até 2 Nodes ou múltiplos discos.
Na prática, o AOS sempre mantém mais cópias dos metadados do que dos próprios dados (3 em RF2, 5 em RF3). O motivo é puramente operacional, o metadado é o índice do storage.
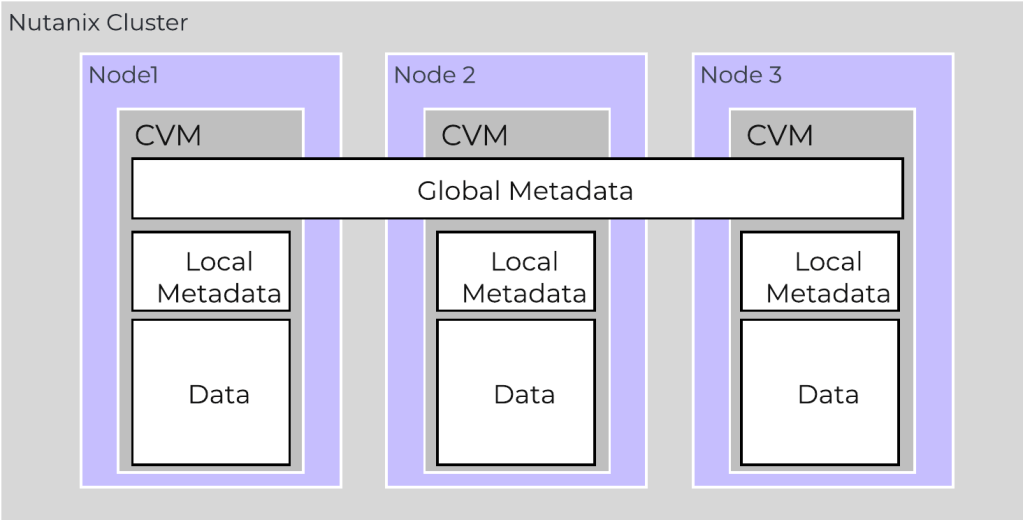
Para manter o IOPS alto e não saturar a rede a cada operação, o motor atual do AOS guarda a parte “quente”desse índice localmente no próprio Node, usando o AES (Autonomous Extent Store). A CVM resolve a leitura ali mesmo. Mas um cluster não pode ter Node discordando entre si. Quando a operação exige atualizar o índice global, o sistema não joga isso direto no banco de dados. Ele aciona o Medusa.
O Medusa é o “tradutor” oficial de metadados da arquitetura. Ele abstrai a complexidade e organiza as informações antes de entregá-las para o Cassandra, o serviço nativo que sincroniza o cluster inteiro em background. Aqui a regra é baseada em quórum. Se caírem Nodes o suficiente para o cluster perder a maioria absoluta dos metadados (metade mais um), o storage simplesmente pausa. É o disjuntor de emergência atuando para evitar um split-brain e garantir que você não acorde no dia seguinte com seus bancos de dados corrompidos.
A genialidade não está apenas em fazer cópias, mas em onde e como o algoritmo as distribui através dos Failure Domains (Domínios de Falha).
O algoritmo do AOS opera com Node Awareness por padrão. Durante uma operação de escrita, o Stargate (nosso daemon de I/O) grava a primeira cópia no SSD/NVMe local e dispara a réplica pela rede. A regra de ouro do Stargate é inegociável, nunca gravar a Cópia 1 e a Cópia 2 no mesmo Node. Se a placa-mãe de um Node queimar, o dado está intacto no vizinho.
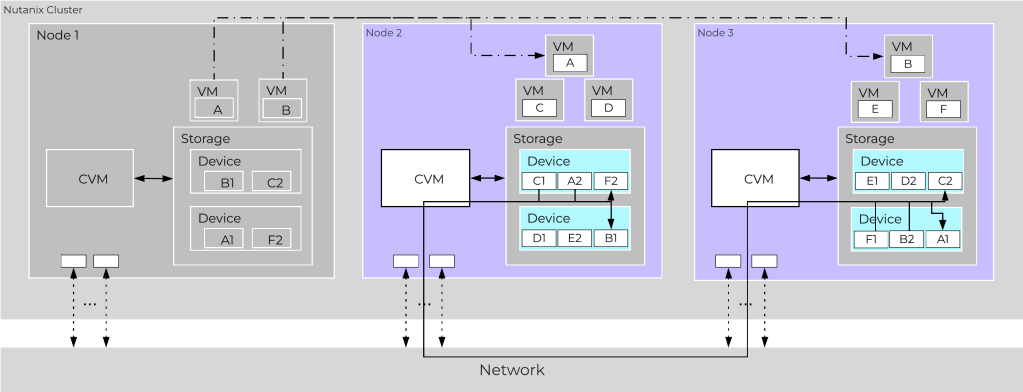
Agora, se o cluster for montado naqueles chassis de múltiplos Nodes (como os tradicionais blocos de 4 Nodes ocupando 2Us e dividindo as mesmas fontes de energia), o AOS percebe isso e tenta escalar para o Block Awareness. A inteligência minimiza o risco, garantindo que as réplicas fiquem em chassis fisicamente diferentes.
A sacada de engenharia aqui é matemática. Para essa proteção de chassi funcionar de fato em um ambiente RF2, seu cluster precisa ter Nodes distribuídos em, no mínimo, 3 blocos (chassis) físicos diferentes. Por quê? Lembra da regra do quórum estrito? Se você tiver Nodes em apenas dois chassis e a régua de energia de um deles falhar, você perde 50% do cluster de uma vez. O quórum dos metadados morre junto. Com 3 gabinetes separados, um chassi inteiro pode apagar e a maioria dos metadados sobrevive intacta nos outros dois.
Podemos elevar essa resiliência um nível acima com o Rack Awareness.
Aqui, o AOS “aprende” a ler a planta física do datacenter. Você mapeia logicamente quais Nodes estão pendurados em quais switches Top-of-Rack (ToR) e em quais réguas de energia (PDUs). A partir desse momento, o algoritmo do Stargate passa a forçar a distribuição das cópias de dados e metadados entre racks físicos distintos.
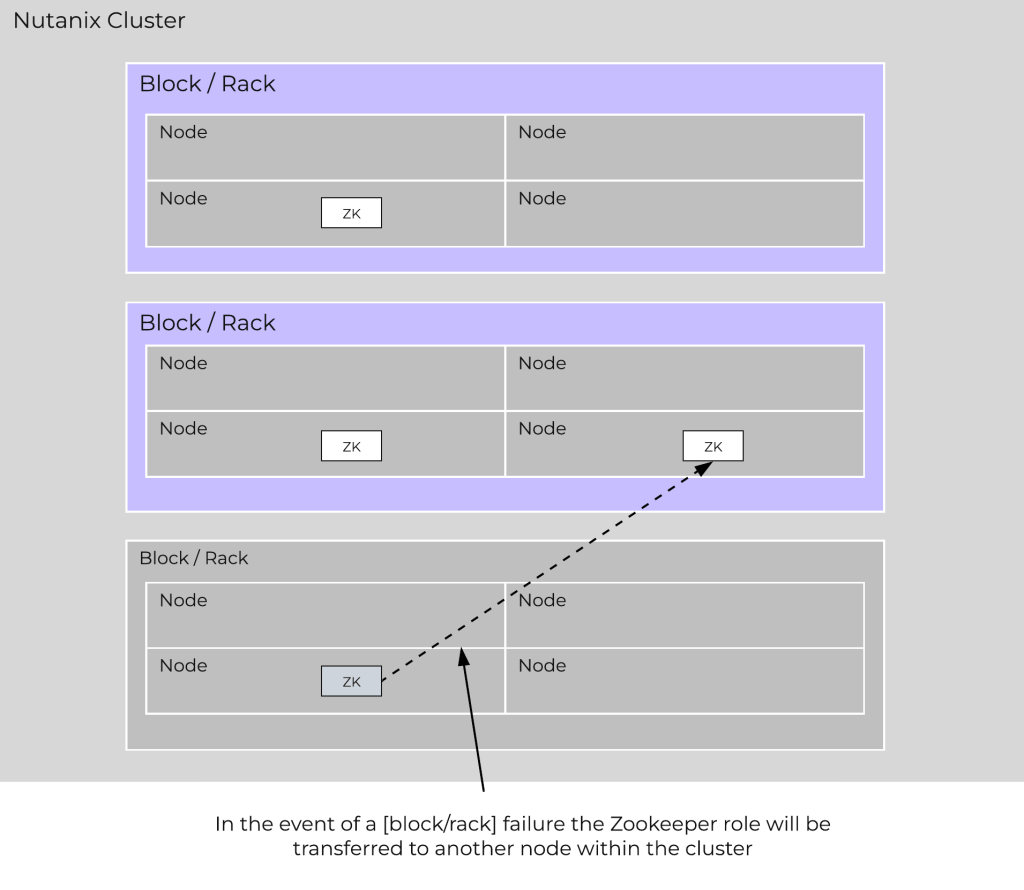
A matemática do quórum continua implacável, para habilitar o Rack Awareness em um ambiente RF2, seu cluster precisa estar distribuído em, no mínimo, 3 racks físicos independentes. Se a arquitetura for RF3, a exigência do algoritmo salta para um mínimo de 5 racks.
O impacto prático dessa arquitetura? Se um switch ToR queimar ou uma manutenção elétrica acidental derrubar a PDU inteira do “Rack A”, você perde vários Nodes ao mesmo tempo. A comunicação física daquele corredor morre. O cluster, no entanto, absorve o impacto. Como a Cópia 2 dos dados e a maioria do quórum dos metadados residem fisicamente nos Racks B e C, o storage não pausa. O hypervisor apenas aciona o HA, religa as VMs afetadas nos racks sobreviventes e a produção continua
A Analogia: O Monomotor vs. O Jato Comercial
Pense em uma viagem de avião.
O modelo tradicional (3-tier com RAID) foi o ápice da engenharia no seu tempo e ainda é super válido em vários cenários. Mas, em termos de resiliência a desastres de hardware, ele é como um avião monomotor. O motor (a controladora do storage ou o chassi principal) é robusto e confiável, mas é um ponto único de falha estrutural. Se esse motor engasgar ou parar em pleno voo, o avião perde sustentação (queda de performance) e você entra em um pouso de emergência, torcendo para não sofrer danos irreversíveis (perda de dados ou corrupção no rebuild).
O modelo hiperconvergente com AOS, RF e Domínios de Falha é como embarcar no último modelo de um jato comercial da Airbus. Ele é projetado com múltiplos motores (nodes/chassis) e sistemas vitais distribuídos. Se um motor pegar fogo lá em cima (um chassi inteiro queimar no rack), os computadores de bordo isolam a falha em milissegundos. Os outros motores assumem a carga, o avião não perde altitude e os passageiros (seus workloads) mal percebem a turbulência. O voo segue normalmente até você pousar em segurança para fazer o reparo.
E aqui precisamos fazer um adendo de realidade. O Nutanix não é feito de mágica. Se o seu datacenter inteiro ficar sem energia ou o ar-condicionado derreter a sala, o “avião” também cai. Mas é inegável que a resiliência e a previsibilidade foram elevadas a um patamar absurdo.
O “prêmio” desse nível de segurança aérea, naturalmente, é pago em peso e combustível (seu espaço útil em disco). Um ambiente RF2 consome 50% da sua capacidade bruta (overhead de 1:1) porque você viaja com tudo duplicado. Um ambiente RF3 consome 66%. Essa é a taxa inegociável que você paga pela tranquilidade de nunca mais depender de um motor só.
Cenário: A Sexta-Feira de Fechamento Contábil
Vamos colocar isso na mesa de operação, na realidade do nosso mercado Brasileiro. Sexta-feira, 22h, último dia do mês. A equipe financeira está rodando pesada o fechamento do ERP. Seu ambiente é o clássico “Padrão BR”, um cluster guerreiro de 4 servidores físicos.
Com a arquitetura legado (3-Tier com SAN/RAID): Essa arquitetura sustentou e ainda sustenta vários datacenters com maestria, mas ela possui um calcanhar de Aquiles estrutural, todo o processamento depende do mesmo chassi de storage centralizado. Imagine que um bug de firmware, uma falha no backplane ou um problema elétrico atípico faça as duas controladoras do storage entrarem em pânico e reiniciarem simultaneamente. O motor principal do avião parou de vez.
O que acontece na prática? Os caminhos de armazenamento caem. Seus hypervisors entram em desespero ao perderem o acesso aos datastores. Seus workloads travam instantaneamente e o banco de dados do ERP fica em estado de suspensão forçada. Quem já passou por isso conhece o pesadelo. Você precisa aguardar o storage inteiro fazer o boot e validar os discos, lidar com dezenas de workloads em estado “órfão” ou “inválido” na sua console de gerência, e muitas vezes precisa dar um reboot forçado nos próprios Nodes de virtualização só para limpar os processos de I/O zumbis. Horas depois, com tudo online, ainda fica o frio na barriga de rodar o check de integridade no banco de dados para garantir que a queda abrupta não corrompeu o fechamento.
Com Nutanix (4 nodes com RF2 e Node Awareness): O cenário de falha severa é o mesmo, mas a arquitetura distribuída muda as regras do jogo. O Node 1 sofre um curto na placa-mãe e morre subitamente (um dos motores do avião parou). O alerta vermelho soa no monitoramento.
Os workloads que estavam rodando especificamente naquele Node 1 sofrem um power off abrupto. Mas aqui entra a resiliência, a camada de storage não parou um milissegundo sequer para os Nodes 2, 3 e 4. O hypervisor percebe a queda, aciona a Alta Disponibilidade (HA) e simplesmente religa os workloads afetados nos Nodes sobreviventes. Como a Cópia 2 dos dados desses workloads já estava espalhada pelos discos dos outros Nodes (graças ao RF2), o acesso ao disco é imediato e garantido. O processo de rebuild começa silenciosamente em background para recriar a Cópia 1 que foi perdida.
A equipe do financeiro experimenta uma pausa de 5 a 10 minutos (o tempo de boot do Sistema Operacional e do banco) e continua o fechamento como se nada tivesse acontecido. Na segunda-feira, a auditoria pede o relatório de incidentes. Você entrega o log mostrando que um hardware morreu, mas zero bytes foram perdidos.
O grande valor da Nutanix não é vender a ilusão mágica de que o ambiente é “imparável”. Hardware é hardware, memórias queimam, cabos rompem e imprevistos acontecem. O verdadeiro valor está no nível de resiliência e em como o software lida com a falha.
No mundo centralizado, a parada do storage derruba e coloca em risco o datacenter inteiro. Na hiperconvergência distribuída, a perda de um Node vira um ticket de troca de peça que você abre enquanto toma um café, porque o sistema conteve a falha e a produção já voltou “sozinha”.
Conclusão Estratégica
A evolução da proteção mecânica (RAID) para a proteção inteligente e distribuída (RF e Domínios de Falha) altera fundamentalmente a relação da empresa com a palavra “Hardware”. Para quem opera o ambiente, a premissa é clara e inegociável, equipamentos físicos vão falhar. Placas-mãe vão entrar em curto, memórias darão erro e fontes vão queimar. A arquitetura corporativa madura não gasta energia tentando criar o “servidor inquebrável”, ela constrói um tecido de software tão resiliente que a quebra física é absorvida o mais rápido possível.
Para o CTO e a diretoria, essa mudança de paradigma vai alé de bits e bytes, traduzindo-se diretamente em sobrevivência corporativa e métricas financeiras. No mundo legado, o risco ao TCO (Custo Total de Propriedade) e ao ROI não está apenas no custo do equipamento, mas no “raio de explosão” de uma falha.
Quando o storage central para, a empresa inteira para. Na arquitetura hiperconvergente, o investimento foca em extrair a máxima resiliência, isolando as falhas. O “seguro” que se paga alocando capacidade de armazenamento para o RF2 ou RF3 é justificado quando comparado ao custo de uma hora de ERP faturando zero ou de uma linha de produção parada. Quando o software contém a falha de forma distribuída, a Continuidade de Negócios é preservada e o RTO (Tempo de Recuperação) despenca de horas de troubleshooting com a empresa fora do ar para os poucos minutos de um reboot automático (HA) dos workloads afetados.
Além dos números, há um ganho significativo na gestão de incidentes. Não sejamos ingênuos, perder um Node físico inteiro sempre vai gerar alerta, dor e estresse na equipe de TI. A diferença está na velocidade e na praticidade da resposta. O que no ambiente 3-tier tradicional seria um incidente complexo, arrastando a equipe para horas de war room tentando ressuscitar LUNs, no Nutanix se torna um incidente contido. O hypervisor religa as máquinas em minutos e o cluster inicia o rebuild sozinho. A equipe de TI deixa de atuar no desespero de restaurar o banco de dados e passa a atuar no controle, monitorando a estabilização do ambiente.
No fim do dia, a verdadeira alta disponibilidade não é sobre possuir máquinas que nunca quebram. É sobre elevar a maturidade da TI, transformando desastres imprevisíveis em eventos operacionais contornáveis e de rápida recuperação. É, definitivamente, trocar o pânico pela previsibilidade.
Reflexão
Antes de desenhar o plano de capacidade do seu próximo ciclo de renovação tecnológica, analise seu ambiente atual:
- Se um disco de alta capacidade (10TB+) falhar hoje na sua infraestrutura, quantos dias seu storage leva para reconstruir a paridade e qual é o impacto direto na latência das aplicações?
- Sua arquitetura possui redundância de controladoras, mas se um chassi inteiro perder energia, onde fisicamente estão as cópias de sobrevivência dos seus dados críticos?
- O espaço “economizado” utilizando topologias de RAID com paridade “frágil” vale o risco financeiro de uma falha dupla durante uma janela de reconstrução?
Este é o terceiro artigo da nossa série dissecando a arquitetura Nutanix. Agora que entendemos o motor por baixo do capô, passando do Data Locality aos Fatores de Replicação, a grande pergunta que fica é como traduzir tudo isso em um desenho de projeto real.
No nosso próximo artigo sobre Nutanix, vamos amarrar todos esses conceitos focando no famoso “Dia 2” da operação. Vamos falar a língua do negócio e mostrar como transformar essa resiliência nativa em um ativo de confiança para auditorias corporativas e entregar a nossa matriz de decisão definitiva de arquitetura. Afinal, quando o RF2 padrão atende bem o seu orçamento e quando o RF3 se torna uma exigência inegociável para o negócio?

Leave a comment