
Nos artigos anteriores, detalhamos como o sistema resolveu o gargalo de I/O com o AOS e consolidou a camada de computação com o AHV. Essa fundação garante a performance e a estabilidade de um cluster isolado. O verdadeiro desafio da equipe de TI, no entanto, ressurge no momento da expansão.
Quando a infraestrutura cresce para múltiplos clusters e sites de contingência, gerenciar cada ambiente de forma isolada fragmenta a administração. O resultado direto dessa falta de centralização é a subutilização de recursos (CAPEX), já que não se tem uma visão unificada do todo, além do aumento na carga de trabalho da equipe de TI.
Para escalar a infraestrutura com uma gestão unificada, a plataforma adota um plano de controle distribuído em duas frentes: o Prism Central e o Prism Element. Isso garante a consolidação das informações e políticas globais, mantendo a independência técnica e operacional de cada cluster.
Prism Element: O Plano de Controle Local
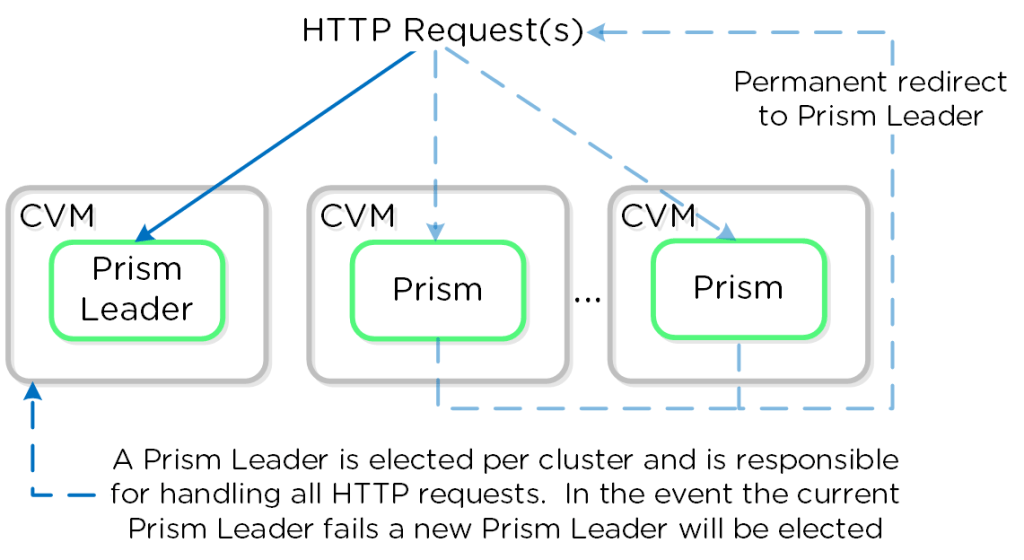
O Prism Element não opera como uma ferramenta de gerência externa. Ele é um serviço nativo que roda de forma distribuída dentro de todas as CVMs (Controller VMs) do cluster. A estrutura foi desenhada com uma abordagem API-first. A interface web opera como um cliente nativo que consome as APIs REST do ecossistema, garantindo que a console gráfica seja apenas uma representação visual direta do estado real do ambiente.
Para simplificar a administração e evitar que a equipe de TI precise mapear qual máquina está ativa, o sistema consolida o acesso através de um VIP (Virtual IP) de cluster. O serviço Prism utiliza um processo interno para eleger uma CVM líder. Esse IP central direciona a conexão automaticamente para a líder daquele momento. Se o Node físico dessa CVM sofrer uma falha, o cluster elege um novo líder e o VIP flutua imediatamente para a CVM eleita. Isso permite que a equipe de TI gerencie o cluster utilizando sempre um único endereço IP, garantindo alta disponibilidade da gerência sem a necessidade de um servidor dedicado.
A interface do Element é o ambiente tático para a operação de Dia 2. A navegação centraliza a integridade do cluster local e elimina a necessidade de alternar entre consoles de fabricantes diferentes. A partir do dashboard principal, a equipe de TI centraliza rotinas fundamentais, que incluem desde a gestão dos Nodes físicos e provisionamento de máquinas virtuais, até a configuração de redes e o controle de snapshots locais.
O limite dessa estrutura isolada é o escopo de atuação. Se a organização cresce e passa a operar nos mesmos cinco clusters distribuídos fisicamente, a equipe de TI precisará gerenciar e autenticar os cinco VIPs separadamente. Isso fragmenta a visibilidade, isola a telemetria e aumenta a complexidade operacional, dificultando a padronização e elevando o risco de inconsistências de configuração entre os ambientes.
Prism Central: O Plano de Controle Global
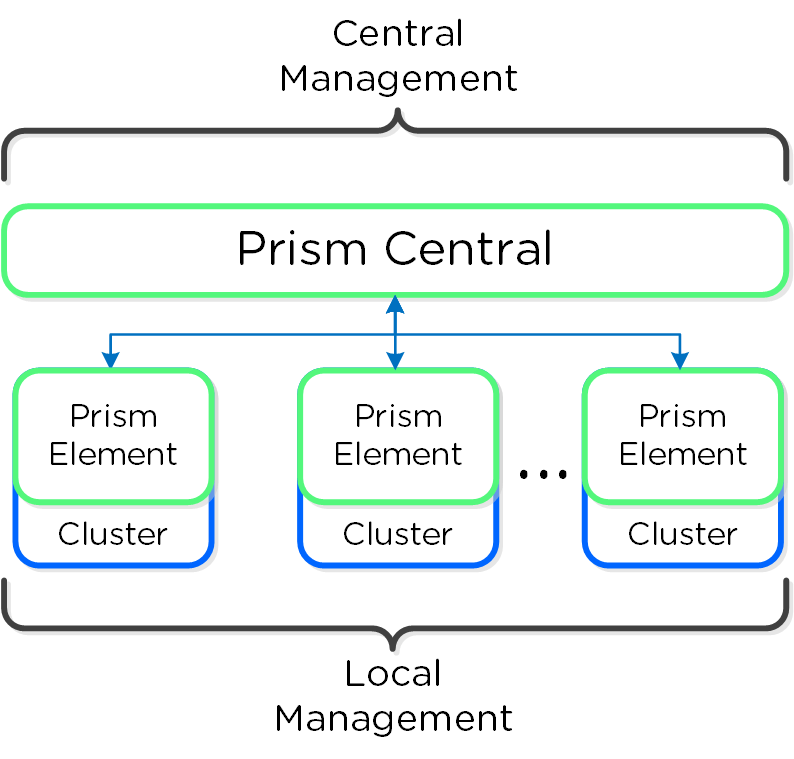
O Prism Central não opera dentro das CVMs locais. Ele é implantado como uma estrutura virtual independente e dedicada para gerenciar múltiplos clusters físicos simultaneamente, funcionando como um plano de controle unificado para todo o ecossistema. Seguindo a mesma filosofia de design do Element, o Central consolida alertas, inventário e métricas de performance de todas as suas localidades em uma única console centralizada, utilizando Single Sign-On (SSO) para o acesso da equipe de TI.
Ao centralizar a coleta de telemetria de todo o ambiente, o Prism Central assume o processamento de cargas analíticas pesadas, preservando os recursos das CVMs de produção de cada cluster local. O motor de inteligência artificial nativo analisa o histórico de consumo global e calcula o Capacity Runway, entregando uma projeção matemática precisa sobre a exaustão de CPU, memória e armazenamento de cada localidade separadamente.
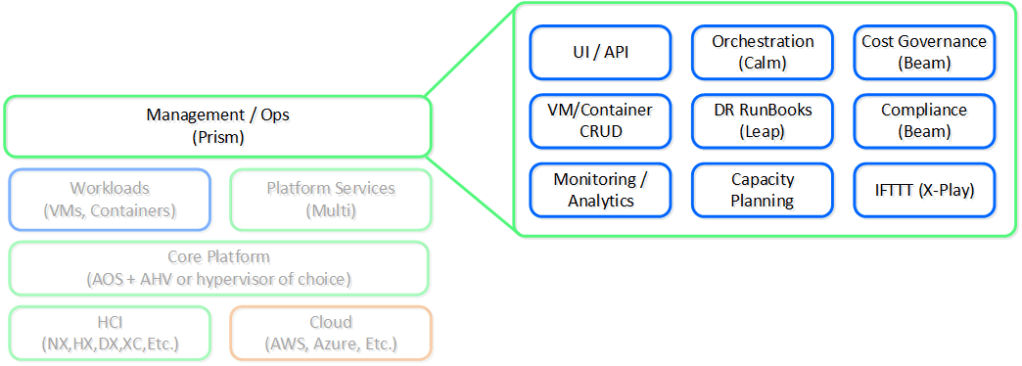
O Prism Central atua como a camada de inteligência e operações da infraestrutura, agregando frentes de automação, governança de custos e orquestração de fluxos de trabalho. Essa centralização transforma a rotina de Dia 2 de múltiplos ambientes físicos ou em nuvem, garantindo uma operação padronizada.
Sob essa ótica global, rotinas de conformidade e controle de acesso (RBAC) são unificadas nativamente. A distribuição de recursos também ganha eficiência de escala: em vez de replicar o upload de ISOs e templates de sistemas operacionais cluster por cluster, o Central gerencia esses ativos através do Image Service centralizado. A plataforma se encarrega de sincronizar e disponibilizar as mídias sob demanda para todo o ecossistema, eliminando tarefas manuais repetitivas e garantindo o alinhamento tecnológico dos ambientes.
Para garantir que essa camada de gerência global não se torne um gargalo ou um ponto único de falha durante a expansão, a arquitetura do Prism Central suporta crescimento horizontal (scale-out). O ecossistema evolui nativamente de uma única VM para um cluster de gerenciamento dedicado e resiliente, dimensionado para suportar e consolidar milhares de máquinas virtuais e contêineres distribuídos sob o mesmo plano de controle.
A Analogia: O Gerente de Loja vs. O Diretor de Operações
Para entender de forma simples: o Prism Element é o gerente de uma loja física. Ele sabe tudo o que acontece ali dentro e resolve os problemas daquele endereço com extrema precisão. O limite é que ele opera isolado e não faz ideia do que ocorre na filial da cidade vizinha.
Já o Prism Central é o diretor de operações na matriz da empresa. Ele olha para um painel que consolida o estoque e as vendas de todas as filiais ao mesmo tempo. Se uma unidade avisa que o espaço dela está acabando, o diretor checa o painel global e vê que outra loja tem espaço de sobra. Em vez de gastar dinheiro alugando um galpão novo do fornecedor, ele ajusta os planos e aproveita o que a empresa já tem.
O grande diferencial dessa visão macro aparece quando a empresa precisa de uma manutenção pesada. Se uma das lojas precisa fechar temporariamente para uma grande reforma planejada, o gerente local não tem como acomodar a operação sozinho. É o diretor na matriz quem organiza a transição: olhando o painel geral com antecedência, ele planeja para quais filiais vizinhas as mercadorias serão direcionadas e onde os funcionários vão trabalhar durante a obra. Isso garante que o atendimento continue funcionando de forma organizada e transparente para o cliente, sem que o negócio precise parar durante a melhoria técnica
O Cenário: O Isolamento de Rede e a Autonomia da Gerência
Imagine uma topologia corporativa com três clusters (Site A, Site B e Site C) distribuídos em localidades físicas diferentes. Na estrutura Nutanix, cada cluster roda o seu próprio Prism Element, garantindo a operação local, enquanto o Prism Central consolida a visão global na matriz.
Durante a madrugada, uma falha de roteamento isola completamente a comunicação do Site C. O link cai e o Prism Central perde o acesso àquela localidade.
Nesse cenário, a operação local não sofre uma interrupção gerencial. A equipe de TI da ponta digita o VIP do Prism Element no navegador e continua administrando o ambiente de forma unificada. O provisionamento de VMs e a alocação de armazenamento seguem respondendo normalmente em uma console que representa o cluster inteiro, porque o plano de controle de resiliência roda embutido nas CVMs dos Nodes locais.
Podemos traçar um paralelo prático com o VMware vSphere. Trata-se de uma plataforma consolidada, mas que adota um modelo de gerência focado em um plano centralizado. Em uma topologia tradicional, um único vCenter na matriz gerencia os três clusters remotamente. Se a rede do Site C cai e o vCenter perde a comunicação, a gerência unificada da filial desaparece. Para criar uma máquina ou analisar um alerta, a equipe de TI é forçada a acessar a interface nativa (Host Client) de cada servidor ESXi individualmente, perdendo a visão de cluster e os recursos de orquestração.
A saída para mitigar esse risco de isolamento no ecossistema VMware é implementar um vCenter Server Appliance em cada localidade e conectar todos através do Enhanced Linked Mode. Essa topologia garante a gerência local unificada em caso de queda de link, mas cobra um pedágio operacional alto: a equipe de TI passa a ter que licenciar, atualizar, monitorar e proteger múltiplos appliances de gerência.
A divisão entre Prism Element e Prism Central entrega a mesma resiliência de um ambiente com múltiplos vCenters em Linked Mode, mas sem a sobrecarga de administração. O plano de controle autônomo já vem nativo no cluster, pronto para operar de forma independente no exato segundo em que o link com a matriz falhar.
Conclusão
A separação entre Prism Element e Prism Central divide a operação local da inteligência global. O Prism Element roda diretamente na borda, focado exclusivamente na resiliência do cluster, entrega de recursos e abstração do hardware. Já o Prism Central atua como o motor de telemetria e governança. Em vez de apenas centralizar telas, ele consolida os dados de múltiplos clusters e usa machine learning para entregar previsibilidade. Na prática, a operação local ganha autonomia total, enquanto a gestão centralizada migra de um modelo reativo para uma abordagem preditiva, orquestrando políticas unificadas e antecipando o esgotamento de recursos antes que eles afetem o negócio.
Reflexão
- Com os prazos longos de entrega de hardware no mercado nacional, o seu gerenciamento atual permite prever matematicamente a exaustão dos clusters com meses de antecedência para abrir o processo de compra a tempo, ou você só descobre o gargalo quando o ambiente já está saturado?
- O cálculo de exaustão de recursos (CPU, memória e storage) dos seus ambientes é automatizado por machine learning para prever cenários futuros ou ainda depende de planilhas manuais e análises reativas de alertas?
- A sua equipe de TI hoje gasta mais tempo sustentando a infraestrutura das próprias ferramentas de gerenciamento ou utilizando a inteligência delas para ditar políticas unificadas de governança?
Nota do Arquiteto
Se você opera a plataforma no dia a dia, sabe que deixamos muitos recursos fora desta discussão. O escopo do Prism Central e do Prism Element vai além do plano de controle básico. É pelo Central que orquestra atualizações de firmware e software via LCM, gerencia o Nutanix Objects, provisionar clusters de Kubernetes, controla a topologia de Disaster Recovery, cria automações com Playbooks e define a microssegmentação de rede com o Flow dentre outras.
Incluir todos esses serviços aqui transformaria o artigo em um manual extenso e tiraria o foco do problema principal. O objetivo deste texto foi isolar a fundação da gerência de clusters e mostrar o impacto operacional de separar o plano de controle. Cada um desses recursos adicionais exige uma análise dedicada e será tratado individualmente nos próximos artigos.
No próximo artigo sobre Nutanix
Com a estrutura de gerência global e local consolidada, o próximo passo é entender como essa fundação acelera a entrega de serviços na ponta. No artigo da próxima semana (Ciclo de Vida da VM e NGT: Agilidade e Consistência), vamos analisar o ecossistema de provisionamento da plataforma.

Leave a comment