
O modelo tradicional de detecção de ameaças na camada de backup sempre foi reativo e descentralizado. O padrão de mercado era agendar varreduras completas após a execução do job, montando discos virtuais em servidores de staging para rodar antivírus de terceiros. Esse desenho técnico funcionava quando as janelas de backup eram longas e o volume de dados era medido em gigabytes. Com a densidade atual de storage e volumes escalando para múltiplos terabytes por máquina virtual, esse fluxo quebra. Montar dezenas de discos após o backup cria um gargalo massivo de I/O, estende a janela de processamento para dentro do horário produtivo e atrasa a identificação de quais pontos de restauração estão de fato íntegros.
Na nossa discussão anterior sobre a matriz de repositórios, focamos em proteger a infraestrutura e garantir que o dado gravado seja imutável, o que significa ter o bloco fisicamente disponível e protegido contra deleção maliciosa. A evolução natural dessa estratégia é ter visibilidade sobre o estado da informação armazenada. O papel do Veeam aqui não é substituir o EDR ou interromper uma infecção ativa na produção que começou horas antes da janela de cópia. A rotina de backup seguirá normalmente até o final para consolidar os blocos no repositório de backup. A mudança operacional consiste em usar o fluxo de transporte para analisar o dado em trânsito, gerando alertas no Malware Detection e marcando aquele ponto específico como infectado caso o motor encontre anomalias. Saímos da proteção passiva do repositório e entramos na camada de observabilidade de dados.
O Fluxo de Dados: Detecção na Camada de Transporte
A mudança estrutural da Veeam está posicionada no ponto de inspeção da informação. Em vez de aguardar a gravação dos dados no repositório final para iniciar a varredura, o motor de processamento executa a análise em trânsito, dividida em duas frentes complementares durante o ciclo de vida do job: o Inline Scan e o Guest Indexing Data Scan. Para viabilizar essa validação sem gerar impacto no desempenho do ambiente produtivo, o fluxo de inteligência foi integrado diretamente ao pipeline de movimentação de blocos.
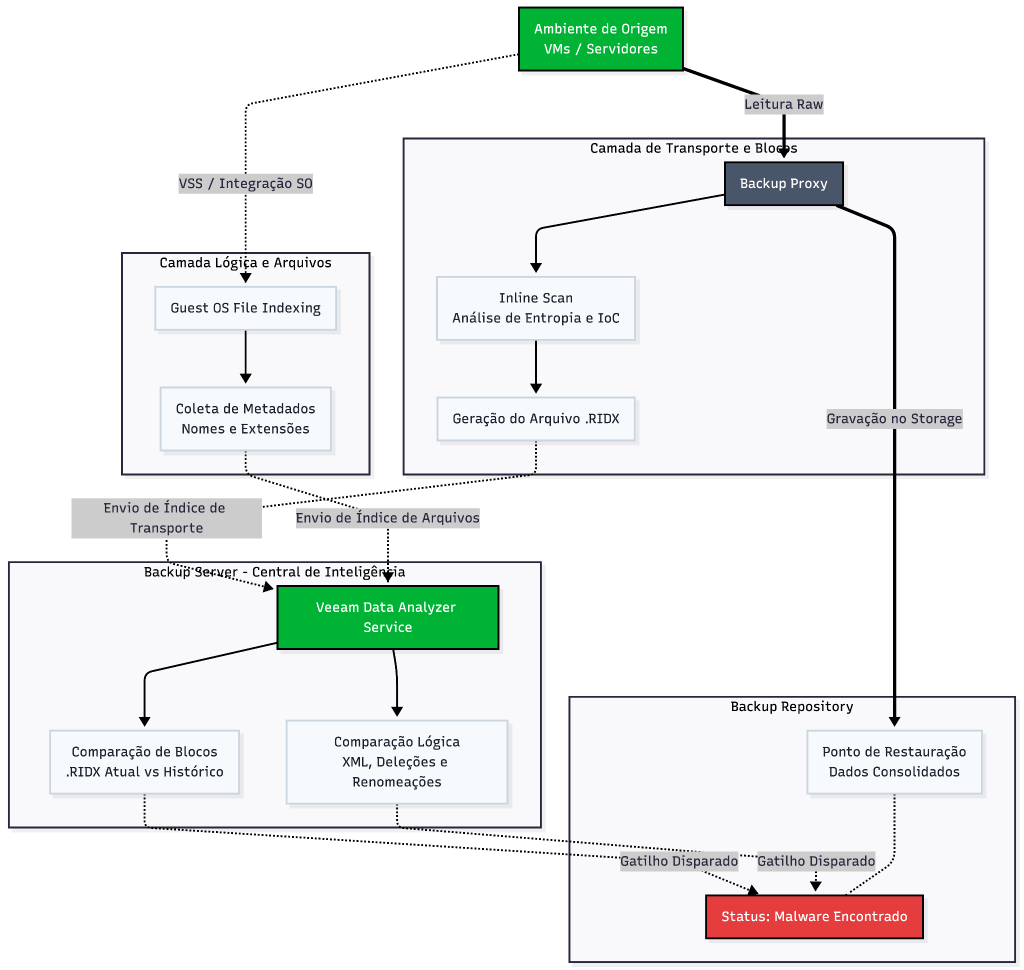
Detecção na Camada de Transporte: Inline Scan e Entropia

O Inline Scan atua diretamente no fluxo de movimentação de blocos durante a execução do backup, processando metadados na memória do Backup Proxy. A operação real combina uma coleta distribuída com uma análise centralizada. Enquanto o proxy transporta os dados, ele analisa em tempo real a entropia matemática dos blocos. Arquivos comuns possuem padrões repetitivos e baixa entropia, enquanto dados criptografados por ransomware apresentam alta entropia e se aproximam da aleatoriedade pura.
Paralelamente, o proxy faz uma inspeção de texto lendo blocos de 4 KB em busca de assinaturas específicas, como notas de resgate conhecidas e endereços Onion da rede Tor. Toda essa anomalia detectada no fluxo é gravada em um arquivo de índice de ransomware temporário com a extensão .ridx para cada disco virtual.
Assim que o job conclui a transferência, o arquivo RIDX é enviado para o servidor de backup. É nesse momento que o serviço do catálogo aciona o motor de análise. O sistema compara o estado do novo ponto de restauração com o histórico da máquina, confrontando as informações contra o ponto mais antigo das últimas 25 horas ou buscando o referencial mais próximo em uma janela de até 30 dias.
A eficiência desse modelo reside no uso de recursos. A coleta de entropia e a inspeção ocorrem na memória do proxy que já está lidando com o dado em trânsito, garantindo que a leitura física no ambiente de produção aconteça apenas uma única vez. Quem consolida o veredito final e atualiza a console do Malware Detection é o servidor central, eliminando o custo de I/O de uma varredura pós-job.
A Camada Lógica: Guest Indexing Data Scan

Enquanto o Inline Scan analisa os blocos em trânsito, o Guest Indexing opera na camada lógica do sistema operacional convidado. Para que o recurso funcione, a infraestrutura exige que a opção Guest OS File Indexing esteja habilitada no job e que o servidor de backup consiga ler o sistema de arquivos da VM.
Durante a rotina, os metadados dos arquivos são consolidados localmente no servidor de backup sob a estrutura do Veeam Guest Catalog. Assim que o job termina, o serviço de catálogo cruza o estado lógico atual da máquina com os pontos históricos através de quatro gatilhos estruturais:
- Arquivos com Extensões e Nomes Suspeitos: O sistema varre o índice confrontando a lista contra um dicionário interno atualizado pela Veeam (o arquivo SuspiciousFiles.xml). Isso mapeia extensões geradas por ransomware e nomes de ferramentas maliciosas conhecidas.
- Indicadores de Comprometimento (IoC): Este motor foca na identificação de notas de resgate nos sistemas de arquivos, procurando por padrões textuais e arquivos de instruções de extorsão deixados nos diretórios.
- Arquivos Deletados em Massa: O analisador calcula o delta entre o índice atual e o histórico. Se o volume de arquivos removidos ultrapassar os limites normais predefinidos para o ambiente, o sistema interpreta o evento como uma rotina de destruição.
- Arquivos Renomeados em Massa: Esse gatilho monitora modificações massivas na estrutura de nomenclatura. O foco é identificar scripts que alteram o nome original dos documentos ou adicionam novas extensões em lote durante a criptografia.
Se qualquer uma dessas regras for violada, o motor atualiza os metadados do ponto de restauração e registra o alerta. Toda essa comparação lógica roda de forma assíncrona no servidor de backup, mantendo o ambiente de produção livre de impacto adicional.
A Analogia: Verificação de Segurança no Aeroporto
Para ilustrar o funcionamento conjunto dessas duas tecnologias, encare o job de backup como o sistema de manuseio de bagagens de um aeroporto, onde o objetivo final é alocar as malas dentro da aeronave, que representa o seu repositório de dados.
Para assegurar que nenhuma ameaça embarque, o sistema aplica dois métodos de vistoria. O Inline Scan atua como o Raio-X da esteira. O fiscal analisa a imagem em tempo real para verificar se a densidade mudou, sem precisar abrir a mala. No software, isso ocorre na velocidade de gravação dos blocos. Se o padrão mudar para uma massa densa e impossível de compactar, o sistema acusa a alta entropia de uma criptografia em andamento.
O Guest Indexing representa um método de vistoria autônomo, equivalente a abrir a bagagem na alfândega. O processo ignora a densidade da imagem e foca na auditoria do inventário interno contra uma lista restrita. Trazendo para a tecnologia, o Guest Indexing entra no sistema de arquivos para mapear o sumiço repentino de milhares de documentos ou a inserção de notas de resgate em formato de texto nas pastas.
O cruzamento contínuo desses métodos reduz substancialmente os alarmes falsos. Se o Inline Scan acusar alta entropia devido a um lote de arquivos naturalmente compactados que entrou no servidor, o sistema descarta o falso positivo ao consultar o Guest Indexing e confirmar que os arquivos mantêm seus nomes e que nenhuma deleção em massa ocorreu. Em contrapartida, se o aumento na entropia vier acompanhado de extensões alteradas confirmadas pelo índice lógico, o sistema crava o alerta vermelho e o ponto recebe a marcação de infecção definitiva na console.
Cenário Prático: A Janela de Backup Sob Ataque
Considere um ataque que começa a criptografar o servidor de arquivos principal da rede corporativa em uma sexta-feira à noite. O job de backup incremental programado para as 22h inicia.
Se a infraestrutura dependesse de varreduras do dia seguinte, o software gravaria os dados corrompidos no repositório e só reportaria o incidente na madrugada de sábado, correndo o risco de não gerar alertas caso o servidor de validação apresentasse gargalos de performance.
Com os motores do v13 habilitados:
- O job inicia e o Data Mover realiza a leitura das alterações.
- O Inline Scan detecta em memória que os blocos modificados possuem taxa de entropia próxima ao limite máximo.
- Simultaneamente, a rotina de Guest Indexing consolida os metadados e valida o dicionário de anomalias, confirmando extensões renomeadas e notas de resgate depositadas no disco.
- O servidor central consolida as métricas e sinaliza imediatamente aquele restore point como “Infected”.
- Os eventos disparam notificações na console e a equipe de TI toma conhecimento da contaminação do restore point antes de tentar qualquer recuperação.
O Veeam não impedirá o uso do ponto para restauração caso seja estritamente necessário. A entrega de valor reside na demarcação visual da linha do tempo. Quando a equipe de TI assume o ambiente para recuperar a operação, a console aponta com precisão qual foi o último ponto de backup limpo e em qual momento os indicadores de comprometimento iniciaram. Isso elimina o trabalho de adivinhação técnica, acelera drasticamente a recuperação e evita o retrabalho de restaurar dados de um ponto cego que já carregava o ransomware.
Conclusão
Segurança em camadas no backup não trata da instalação de novos agentes operacionais. O objetivo é extrair inteligência técnica do fluxo de dados que a infraestrutura já transporta todas as noites. A união de análise de entropia inline com a inspeção lógica de índices entrega uma linha de defesa independente da saúde do sistema operacional de origem. Isso reduz o tempo de resposta e assegura que a métrica de RTO da empresa seja gasta voltando serviços críticos, e não investigando qual bloco está utilizável.
Nota do Arquiteto
É indispensável definir as linhas de responsabilidade técnica entre as disciplinas de infraestrutura e segurança. A plataforma da Veeam não substitui soluções de resposta em endpoints (EDR/XDR) ou o monitoramento constante por um SOC. Isolar e interromper o processo de infecção nos servidores de produção é função primária do ecossistema de proteção ativa. A missão do Veeam é mapear o desastre cronologicamente e guiar a equipe de TI até o ponto de recuperação saudável mais recente.
Adicionalmente, a equipe de TI não deve iniciar uma restauração maciça de dados de forma autônoma durante um incidente. O acionamento da restauração exige a aprovação do time de segurança. Voltar um backup íntegro para um ambiente onde a credencial vazada não foi revogada ou a vulnerabilidade de borda não foi mitigada fará com que os dados limpos sejam criptografados novamente em questão de horas.
Reflexões
- Se um servidor crítico sofrer criptografia massiva agora, quanto tempo o seu sistema de backup atual demorará para alertar que os dados que estão sendo salvos nesta noite já estão comprometidos?
- A sua solução atual executa a análise de malware de forma ativa durante a leitura de trânsito dos dados, ou apenas transfere blocos e delega a segurança para validações do dia seguinte?
- O plano de resposta a incidentes da sua corporação prevê o que fazer se o ponto de restauração mais recente for sinalizado como infectado, ou a equipe de TI tentará iniciar a recuperação às cegas por falta de visibilidade temporal?
No próximo artigo sobre Veeam
Agora que cobrimos como os mecanismos mapeiam e delimitam a linha do tempo de um incidente durante a janela de backup, o avanço natural é a mecânica de restauração.
No próximo conteúdo, detalharemos os conceitos de Secure Restore e a funcionalidade do Veeam Threat Hunter. O objetivo será entender os gatilhos finais de validação exigidos antes de devolver o dado para a produção, executando scripts YARA e cruzamentos usando o motor proprietário do Veeam Threat Hunter para garantir que você não reintroduza um código malicioso ou uma backdoor adormecida durante o processo de restauração.

Leave a comment